The ‘Panama Papers’ is a dataset of 11.5 million documents and records regarding offshore entities. It was leaked in 2015 and the first news stories analysing its contents published in early 2016. It was made available to the International Consortium of Investigative Journalists (ICIJ), who in turn have analysed it and made available a curated set of the data (‘_the ICIJ Offshore Leaks database_’) here. One of the challenges with a raw dataset such as the one that was leaked is how to analyse it. Offshore entities can be ‘layered’ so that the ultimate owner or beneficiary is not clear unless you resolve all the links in the chain. You may find individual entities that appear innocuous but turn out to share the same address as a dozen others, which in turn are intermediaries for other entities that are of interest. So how to best decipher this maze of relationships?
Enter graph analytics. This is not a new technology or concept, but one which has possibly passed some of us in the relational database world by. And just to clarify, by graph, I mean this:  not this:
not this:  . One of the key things for me is that it enables the discovery of implicit or latent relationships in data that would otherwise only be realised if explicitly and individually searched for. Instead of looking at data in terms of a set of columns grouped together on a row in a table, possibly related to other rows on other tables by a common key, graph analysis looks at nodes and edges and how they relate. This alternative way of modelling and querying data gives rise to algorithms and analysis that would be impossible - or highly inefficient and unscalable - if run as a standard SQL query against relational data.
. One of the key things for me is that it enables the discovery of implicit or latent relationships in data that would otherwise only be realised if explicitly and individually searched for. Instead of looking at data in terms of a set of columns grouped together on a row in a table, possibly related to other rows on other tables by a common key, graph analysis looks at nodes and edges and how they relate. This alternative way of modelling and querying data gives rise to algorithms and analysis that would be impossible - or highly inefficient and unscalable - if run as a standard SQL query against relational data.
In this article we’ll see how Oracle’s Big Data Spatial and Graph can be used to store the Panama Papers dataset in a graph database, and then analyse it with graph tools. Oracle Big Data Spatial and Graph provides a graph database built on top of Apache HBase or Oracle NoSQL, and an in-memory analytics engine with dozens of pre-defined algorithms. It also includes capabilities for storing and analysing spatial data using the Hadoop framework, but that’s outside the scope of this article.
Within the published database is a list of nodes - addresses, entities, intermediaries, and people (‘officers’), along with a list of how these all relate (known as the edges). Here is an example of the node/edge relationships:
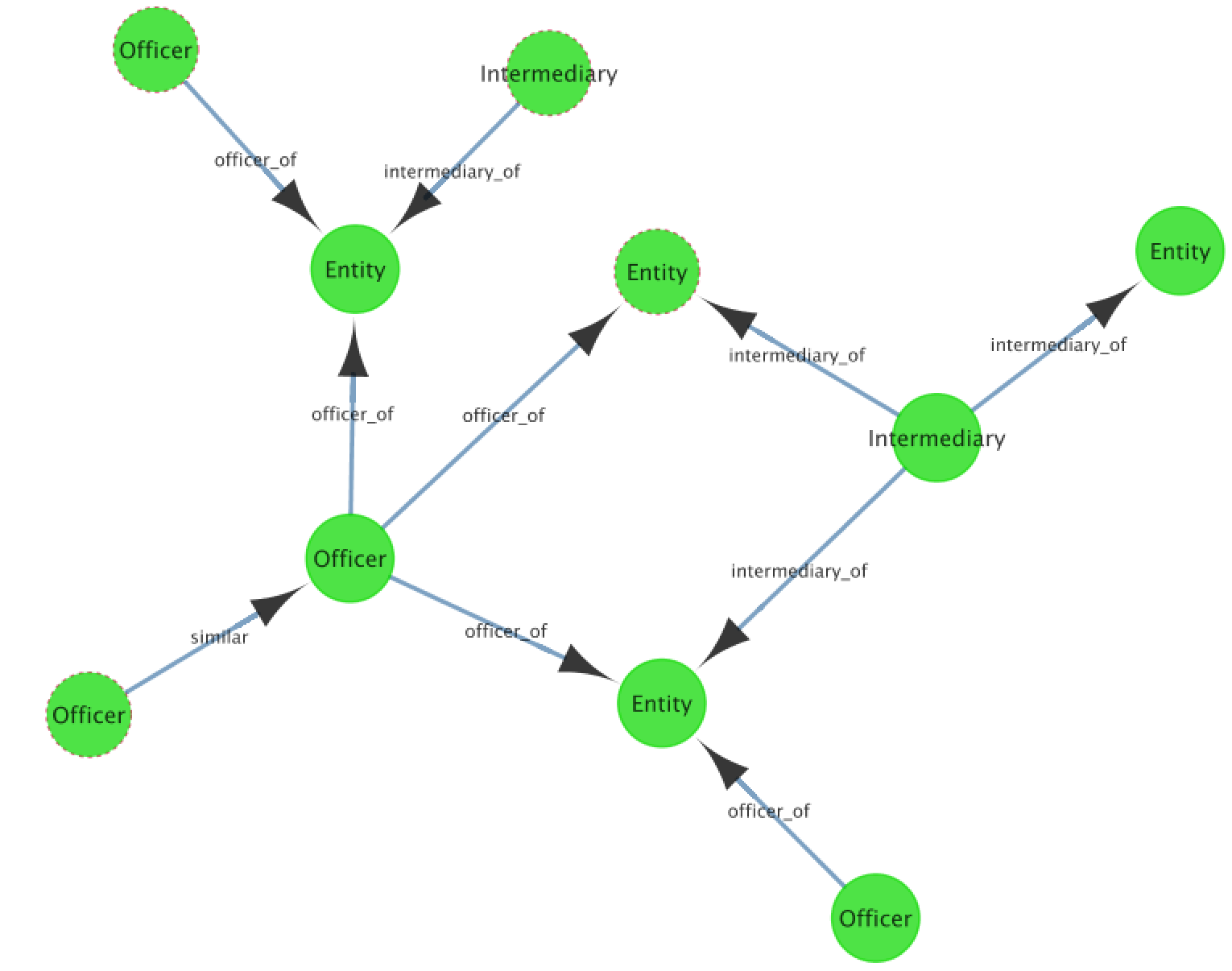
Once these relationships are expanded out and followed, we can visualise networks of the various records within the dataset and start to see how they relate:
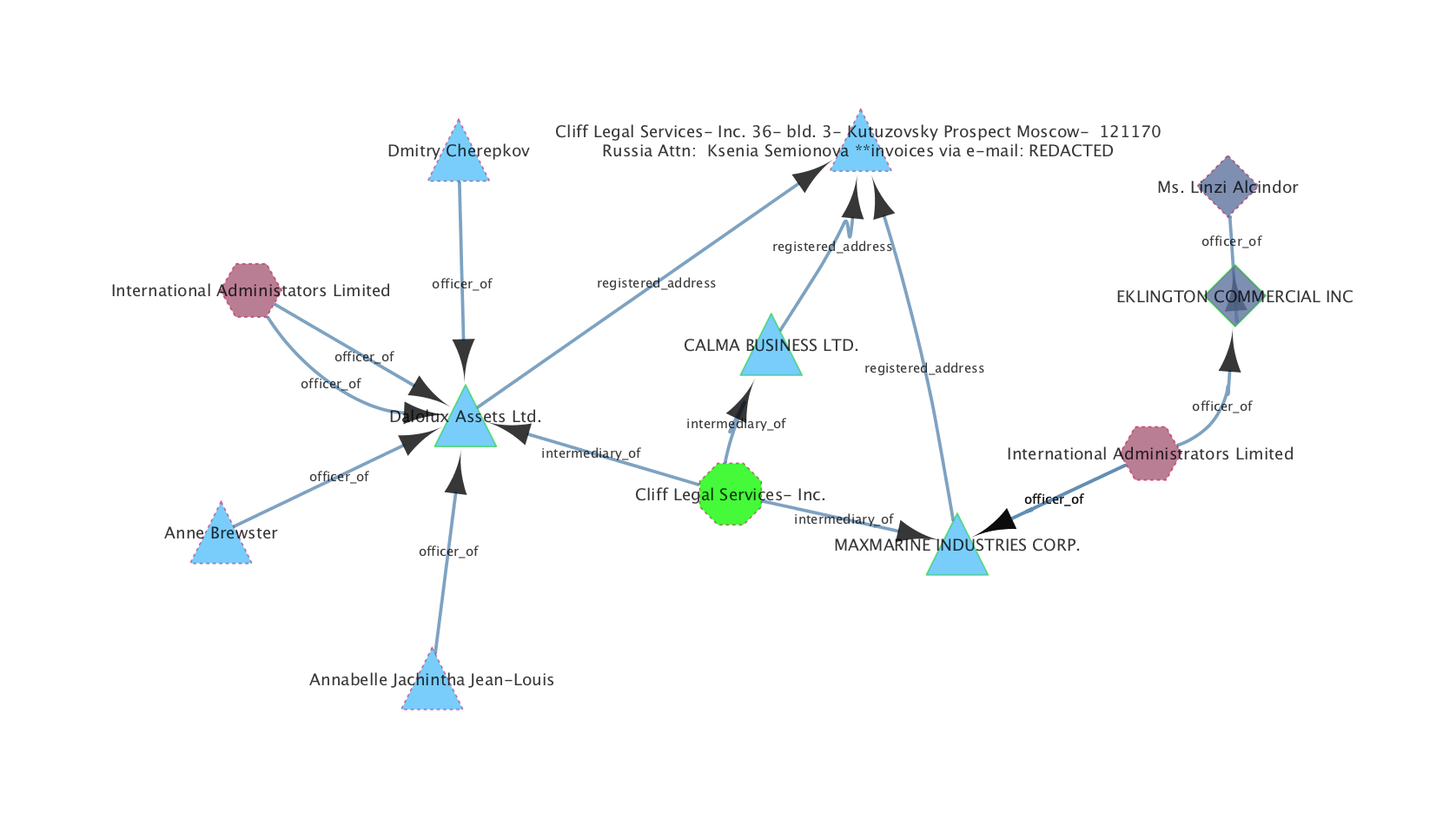
The visualisations shown here are generated using Cytoscape, which with the necessary plugin for Oracle Big Data Spatial and Graph, hooks into the API and runs queries against it using the in-memory analysis engine, rendering the results.
For more background on the Panama Papers data leak and the papers, see the coverage in newspapers including The Guardian, New York Times, as well as Wikipedia. It’s important to re-iterate this caveat from the ICIJ :
There are legitimate uses for offshore companies and trusts. We do not intend to suggest or imply that any persons, companies or other entities included in the ICIJ Offshore Leaks Database have broken the law or otherwise acted improperly. Many people and entities have the same or similar names.
Environment
Oracle Big Data Spatial and Graph can be installed on the Oracle Big Data Appliance, or on commodity-hardware Cloudera cluster. In the examples shown in the article I’m using the BigDataLite 4.5 VM from Oracle, along with CytoScape 3.4 and the plugin from Oracle which enables Property Graph support in Cytoscape for Big Data Spatial and Graph.
Preparing the data
There are five datasets; four sets of node data, and one edge (relationship).
-rw-rw-r--@ 1 rmoff staff 26535755 May 9 15:42 Addresses.csv
-rw-rw-r--@ 1 rmoff staff 106940060 May 9 15:42 Entities.csv
-rw-rw-r--@ 1 rmoff staff 3668297 May 9 15:42 Intermediaries.csv
-rw-rw-r--@ 1 rmoff staff 43467573 May 9 15:42 Officers.csv
-rw-rw-r--@ 1 rmoff staff 39388834 May 9 18:16 all_edges.csv
Taking one of the node files, Addresses.csv, the headers are declared, which makes life easier:
The node_id column gives us our key, which is used in the all_edges.csv file to declare the relationships. For example:
10000055,registered_address,14091544
gives us the directed edge definition; node 10000055 (“SEG MECHANICAL LTD” in Entities.csv) has the registered address of node 14091544 (“EUROFIN SERVICES” in Addresses.csv).
So far, so relational. But now we want to take this data and load it into our property graph database, in Oracle Big Data Spatial and Graph. We’ll do this by wrangling the data into the Oracle Flat File Format. In this format each node has one row per property - it is in effect a set of key/value attributes for each node. A node is going to have at least two properties (values) : its value, such as the entity name, and its type, such as ‘Entity’, ‘Address’ etc. Some nodes may well have more, such as country information, and so on. The format is slightly esoteric, in that it’s comma-separated but with data stored in different columns depending on its type (string/numeric/date). I presume this makes for efficient and easy parsing by the loader, but it does put all the work on the producer of the file ;-)
Taking a simple example from the Addresses file, we want to convert this source record:

into this set of key/value records in Oracle Flat File format:

with the resulting CSV on disk looking like this:
67423,Type,1,Address,,
67423,Name,1,"Apt.92, Minskaya Str, 1G,Bldg1, Moscow Russia",,
67423,Country Codes,1,RUS,,
67423,Country,1,Russian Federation,,
67423,Source ID,1,Offshore Leaks,,
67423,Valid Until,1,The Offshore Leaks data is current through 2010,,
The trailing commas are important - these are the empty placeholder columns for numeric and date values.
Here is one of the relatively unspoken dirty truths about working with “big data”: a lot of the time is spent simply formatting, filtering, and shaping data so as to get it in a form ready to work with. Frequently known as data “wrangling” or “munging”, there are a variety of ways to do it, but all generally based on a toolbox of techniques and tools with the appropriate one chosen for the particular job at hand. Often this would be Python and the pandas library, or R, or even bash. There is much that can be done with awk, sed, and grep alone.
Since the source dataset is static (it was a one-off leak; we aren’t expecting any updates), the preparation that I do to get the data ready to import can be one-off. I ended up doing the transformation in R - see the code on gist here. It’s not pretty, but it gets the job done. Obviously, it would benefit from some severe refactoring (a.k.a. rewrite from scratch) to remove the code duplication and move it into a function.
So the above transformation gives us our nodes file, which by convention is suffixed opv - the v standing for ‘vertices’ which is what nodes are also known as in graph terminology.
The edges transformation is more simple. We simply need to generate a unique key for each edge, and change the order of the columns from the source file. Edges can also have properties. For example, if the edge were “Fred owes money to Bob”, the property of the edge could be the amount, as well as the date of the loan etc. In this particular dataset none of the edges have properties, and we need to mark that in the file we create.
The source edge file looks like this:

which after transformation is:

and the resulting output file (with ope suffix):
1,11000001,10208879,intermediary_of,%20,,,,
2,11000001,10198662,intermediary_of,%20,,,,
So, we’ve now got two files in Oracle Flat File format, ready for import to the property graph database. Wrangling the data in R has given us the ability to quickly get the data into the format we need to do further analysis; if we were going to build this as part of a data pipeline in production we’d obviously move the work into a tool such as Oracle Data Integrator so as to be able to integrate, schedule, and maintain the pipeline alongside others.
Importing the data
Our two source files are panama_nodes.opv and panama_edges.ope:
$ wc -l panama_*
1265690 panama\_edges.ope
8254548 panama\_nodes.opv
9520238 total
$ head -n2 panama_*
==> panama\_edges.ope \<==
568498,11000001,10208879,intermediary\_of,%20,,,,
568499,11000001,10198662,intermediary\_of,%20,,,,
==> panama\_nodes.opv \<==
1,Type,1,Officer,,
1,Name,1,Peter Sabourin,,
We’re going to load these into Oracle’s Property Graph stored in Apache HBase. Before we do this, we need to ensure that the necessary services are running. On BigDataLite VM run /opt/bin/services and use the dialog - on your own cluster you can use Cloudera Manager or equivalent. Make sure that the following are running:
- HBase
- Zookeeper
- HDFS
- YARN
- Solr (optional)
Now we’ll launch the java-based command line tool, gremlin:
/opt/oracle/oracle-spatial-graph/property_graph/dal/groovy/gremlin-opg-hbase.sh
From the gremlin prompt, we define the configuration for our graph database:
cfg = GraphConfigBuilder.forPropertyGraphHbase() \
.setName("panama") \
.setZkQuorum("bigdatalite").setZkClientPort(2181) \
.setZkSessionTimeout(120000).setInitialEdgeNumRegions(3) \
.setInitialVertexNumRegions(3).setSplitsPerRegion(1) \
.build();
Important values here are setName to define the database name (“panama” in this case), and setZkQuorum for the host running Zookeeper. Having defined the configuration object, we can now instantiate a connection to the database:
opg = OraclePropertyGraph.getInstance(cfg);
If you have already loaded some data and want to reset it to the empty state, you can optionally run :
// Don't run this unless you want to delete
// the contents of your property graph database
opg.clearRepository();
Now we can load our data. First up, define variables specifying the local filesystem path to where the node and edge files reside:
vfile="/u02/custom/panama_nodes.opv"
efile="/u02/custom/panama_edges.ope"
Create a data loader instance:
opgdl=OraclePropertyGraphDataLoader.getInstance();
and now run the load:
opgdl.loadData(opg, vfile, efile, 2);
If you’re using the full set of records this is going to take a bit of time (15–30 minutes or so). Once loaded, you can run queries to show how many nodes and edges have been loaded to the graph database:
opg-hbase> opg.countEdges();
==>1265690
opg-hbase> opg.countVertices();
==>838105
Under the covers the data’s been stored in the database specified - Apache HBase. We can see which HBase table:
opg-hbase> opg.getVertexTabName()
==>panama_allVT.
opg-hbase> opg.getEdgeTabName()
==>panama_allGE.
And even see its underlying contents through Hue if we really wanted to:
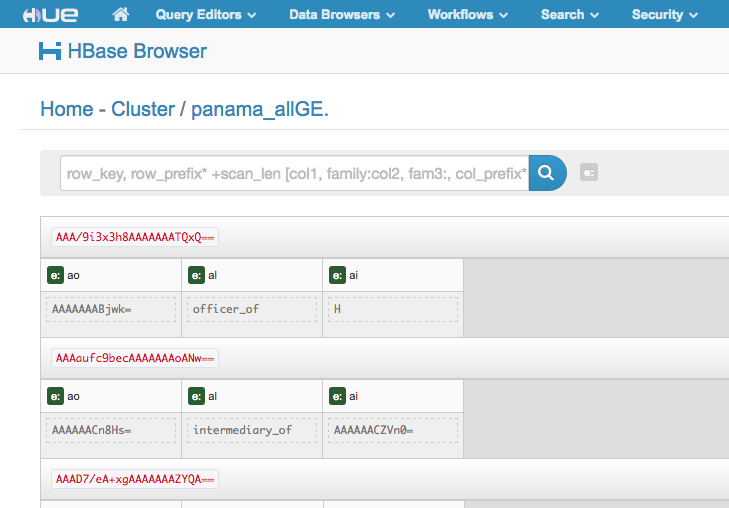
Now we’ve loaded the data into our graph database. Yay! Now … let’s make use of it. I’ll demonstrate two routes to take, depending on the purpose of your analysis.
Graph Analysis by API
Oracle Big Data Spatial and Graph consists of the graph database, a data access layer (DAL), and an in-memory analysis engine.
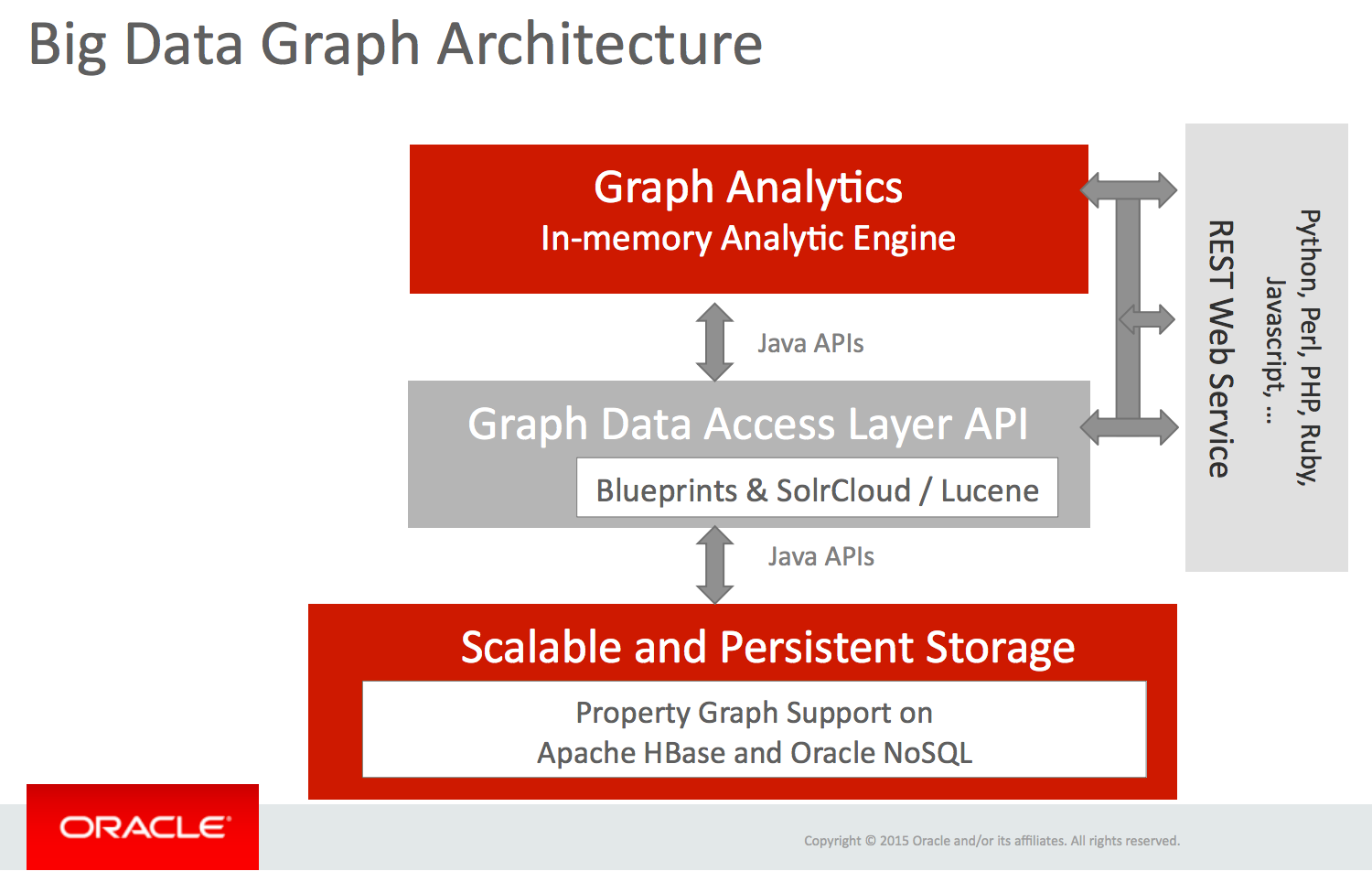
(image source)
Simple interrogation of the data can be performed against the DAL, or actual graph analytics using the in-memory agent and its provided graph analysis algorithms.
Before we look at the code, let’s re-iterate the caveat for this data:
There are legitimate uses for offshore companies and trusts. We do not intend to suggest or imply that any persons, companies or other entities included in the ICIJ Offshore Leaks Database have broken the law or otherwise acted improperly. Many people and entities have the same or similar names.
Here’s a simple example of returning the value of a vertex, using the DAL from the Gremlin shell. After launching gremlin, we first we set up the instance into which we previously loaded data:
// Same configuration object as used previously when
// populating the graph
cfg = GraphConfigBuilder.forPropertyGraphHbase() \
.setName("panama") \
.setZkQuorum("bigdatalite").setZkClientPort(2181) \
.setZkSessionTimeout(120000).setInitialEdgeNumRegions(3) \
.setInitialVertexNumRegions(3).setSplitsPerRegion(1) \
.build();
// Create an instance of the OraclePropertyGraph (https://docs.oracle.com/cd/E65728_01/doc.43/e62126/oracle/pg/hbase/OraclePropertyGraph.html)
opg = OraclePropertyGraph.getInstance(cfg);
Now we run a query to return details for a specific vertex (node):
and list a specific property:
opg-hbase> opg.getVertex(236724).getProperty("Name");
==>Portcullis TrustNet Chambers P.O. Box 3444 Road Town- Tortola British Virgin Islands (w.e.f 9 December 2005)
To search through nodes for those that match a particular key/value use the getVertices method, overloaded with the key/value - if you don’t do this you get all vertices which can take a while:
opg-hbase> opg.getVertices("Country","Virgin Islands- British");
==>Vertex ID 236704 {Country:str:Virgin Islands- British, Country Codes:str:VGB, ID:int:236704, Name:str:Shellbourne Trust Company (BVI) Limited Road Town- Tortola British Virgin Islands, Source ID:str:Offshore Leaks, Type:str:Address}
==>Vertex ID 237024 {Country:str:Virgin Islands- British, Country Codes:str:VGB, ID:int:237024, Name:str:Columbus Centre Building- Wickham Cay- Road Town Tortola- British Virgin Islands., Source ID:str:Offshore Leaks, Type:str:Address}
==>Vertex ID 237184 {Country:str:Virgin Islands- British, Country Codes:str:VGB, ID:int:237184, Name:str:FINC Building Sea Cow's Bay P.O. Box 288- Road Town Tortola- BVI, Source ID:str:Offshore Leaks, Type:str:Address}
[...]
Now let’s do some actual graph analysis. First off, we need to instantiate a session with the in-memory analysis engine (PGX), an Analyst instance to perform the analyses, and load our graph into the in-memory session:
opg-hbase> session = Pgx.createSession("session-id-1");
==>PGX session '4d0b5898-34b1-469b-9c37-9883cb6b5fd3' registered at PGX Server Instance running in embedded mode
opg-hbase> analyst = session.createAnalyst();
==>Analyst for PGX session '4d0b5898-34b1-469b-9c37-9883cb6b5fd3' registered at PGX Server Instance running in embedded mode
opg-hbase> graph = session.readGraphWithProperties(cfg);
==>PGX Graph named 'panama' bound to PGX session '4d0b5898-34b1-469b-9c37-9883cb6b5fd3' registered at PGX Server Instance running in embedded mode
There are dozens of built-in graph analysis algorithms in the PGX engine, including PageRank, which is one way of determining which vertices have the most importance in network:
opg-hbase> rank = analyst.pagerank(graph, 0.001, 0.85, 100);
==>Vertex Property named 'pagerank' of type double belonging to graph panama
opg-hbase> rank.getTopKValues(2);
==>PgxVertex with ID 236724=0.010566401851781617
==>PgxVertex with ID 288469=0.001078665956117294
This gives us the id of the top two ranked vertices - and to find out the details of these we use the getVertex method seen above:
opg-hbase> opg.getVertex(288469).getProperty("Name");
==>Unitrust Corporate Services Ltd. John Humphries House- Room 304 4-10 Stockwell Street- Greenwich London SE10 9JN
opg-hbase> opg.getVertex(288469).getProperty("Type");
==>Address
Looking at the degree centrality of a graph enables us to see how many connections a vertex has, and thus identify in another way to pagerank which vertices are most ‘important’:
opg-hbase> c = analyst.degreeCentrality(graph);
==>Vertex Property named 'degree' of type integer belonging to graph panama_all
opg-hbase> c.getTopKValues(5)
==>PgxVertex with ID 236724=37338
==>PgxVertex with ID 54662=36374
==>PgxVertex with ID 11001746=7016
==>PgxVertex with ID 298333=5700
==>PgxVertex with ID 288469=5699
opg-hbase> opg.getVertex(236724).getProperty("Name");
==>Portcullis TrustNet Chambers P.O. Box 3444 Road Town- Tortola British Virgin Islands (w.e.f 9 December 2005)
opg-hbase> opg.getVertex(236724).getProperty("Type");
==>Address
opg-hbase> opg.getVertex(54662).getProperty("Name");
==>Portcullis TrustNet (BVI) Limited
opg-hbase> opg.getVertex(54662).getProperty("Type");
==>Intermediary
Degree centrality can be categorised further based on the direction of edges connecting the vertices
opg-hbase> analyst.outDegreeCentrality(graph).getTopKValues(1)
==>PgxVertex with ID 54662=36373
opg-hbase> analyst.inDegreeCentrality(graph).getTopKValues(1)
==>PgxVertex with ID 236724=37338
You’ll notice from this that vertices 54662 and 236724 are the the top ranked vertices by outbound/inbound edge connections respectively, and that these both appear in the degreeCentrality results above too. 236724 is an Address, and thus vertices connected in to it as the address for a given entity, whilst 54662 is an Intermediary of and thus connected out to other entity or intermediary vertices.
To put the above data that shows the number of connections to the most-connected vertices, we can use another function to calculate how many vertices have the same number of connections:
opg-hbase> analyst.inDegreeDistribution(graph).get(1)
==>258556
opg-hbase> analyst.inDegreeDistribution(graph).get(2)
==>89600
opg-hbase> analyst.inDegreeDistribution(graph).get(30)
==>35
So this is good, and we can use this programmatically to extract vertices and their details from our graph based on the algorithms that we run. But what about the more ad-hoc discovery and exploratory analysis work? This is where Cytoscape comes in.
Graph Analysis through Cytoscape
Cytoscape is an open source tool for visualising networks. It’s extendable with plugins, and Oracle have written one that enable it to extract and interact with graphs stored in Big Data Spatial and Graph, on Apache HBase or Oracle NoSQL. We can use it to get an initial view of a network, and expand it out and explore it further.
The plugin (“Property Graph Support for Cytoscape”) is available to download here, and you can find a sample of the configuration file that I’ve used with BigDataLite 4.5 here
After launching Cytoscape, go to File > Load > Property Graph > Connect to Apache HBase Database. Specify the Zookeeper details, and then click on the magnifying glass/search icon next to Graph Name - this will cause Cytoscape to connect to Zookeeper to get the HBase details, and if everything’s working correctly you’ll get a list of the graphs currently defined.
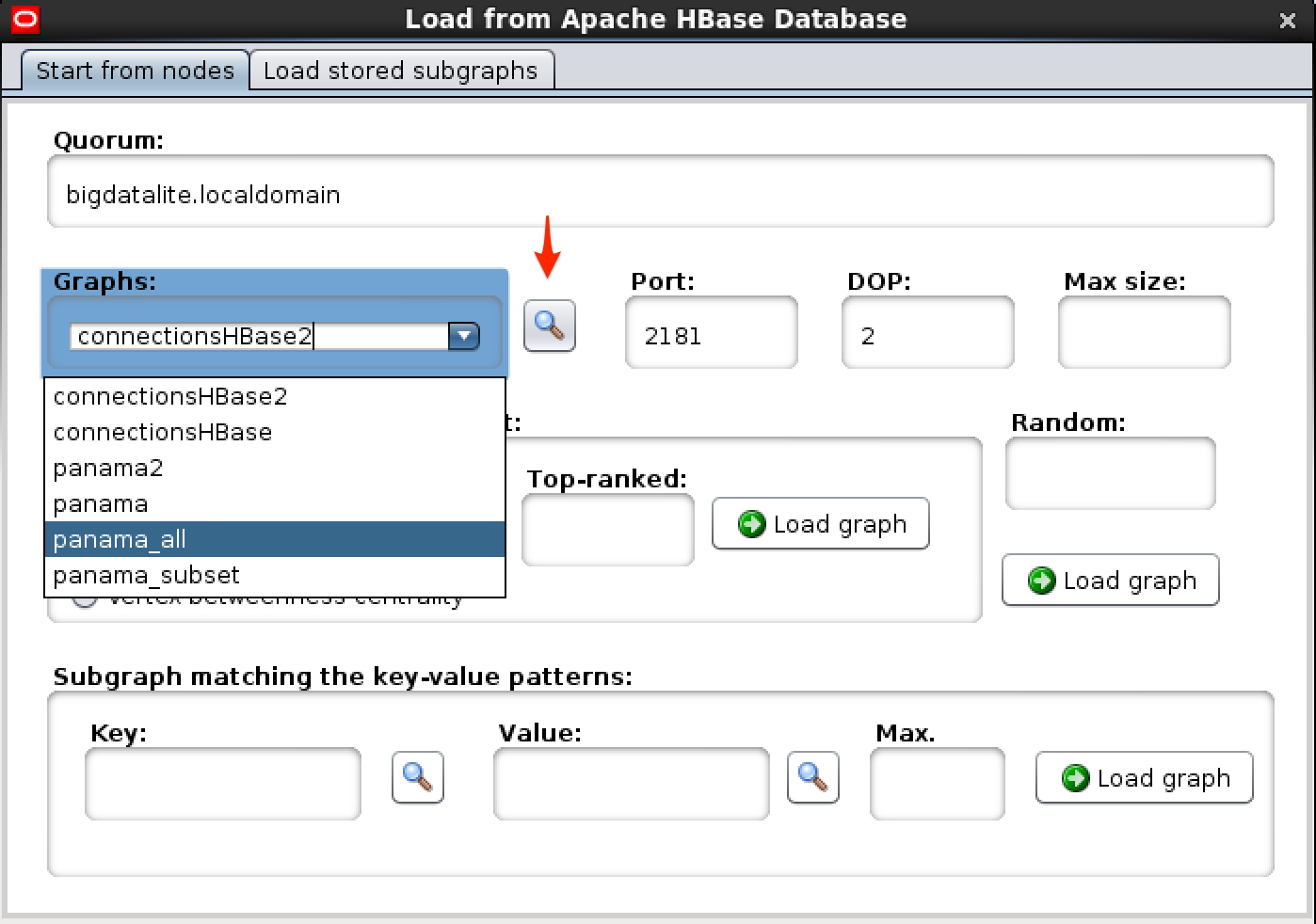
You now need to decide from where you want to start your analysis, choosing one of:
- Run an analysis algorithm, such as page rank
- Select a random number of nodes
- Search based on key/value pairs
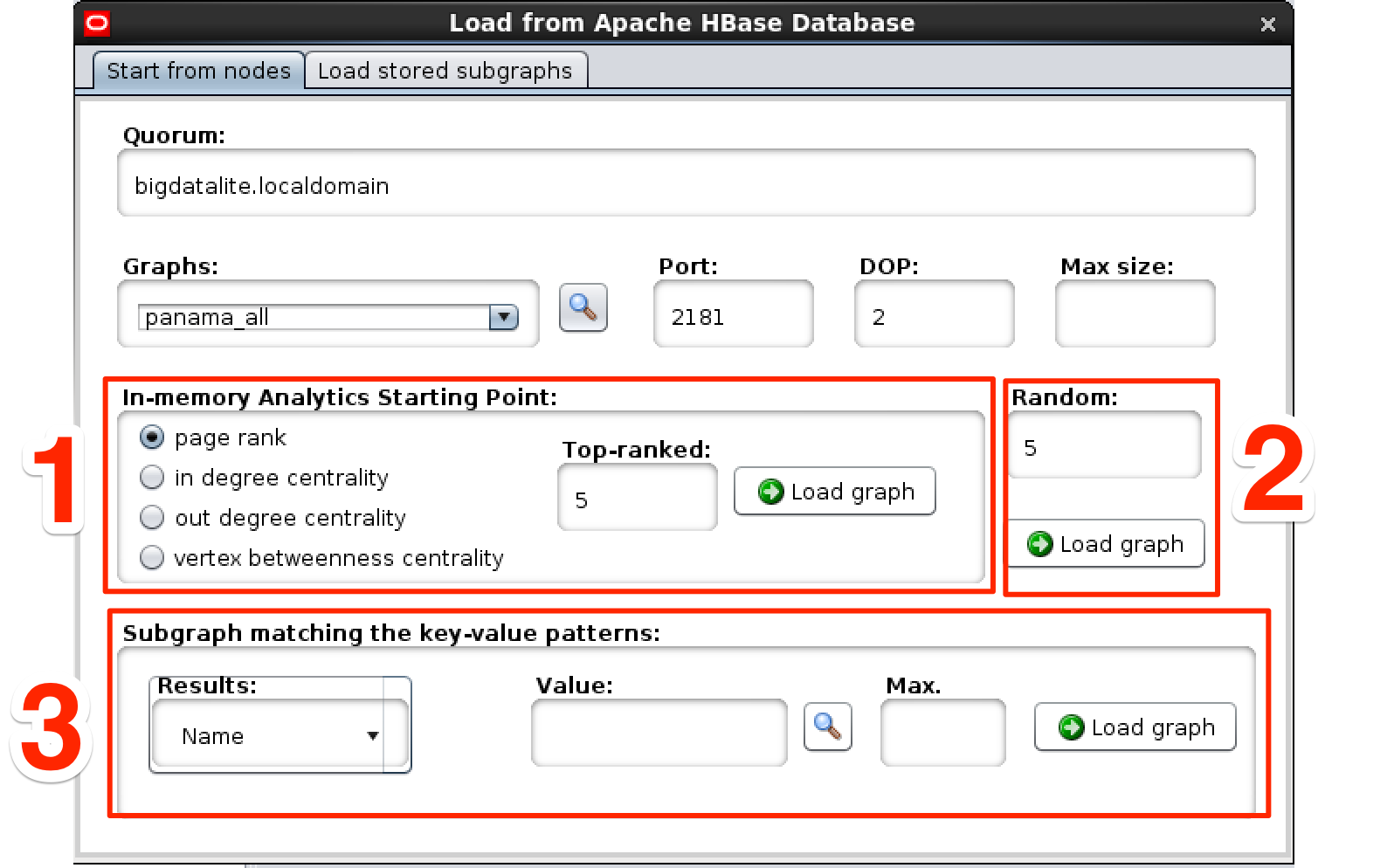
Cytoscape then uses the PGX in-memory analyst to retrieve the initial set of nodes, which will look pretty uninteresting:

Right-click on the graph background, and from Apps > Show label value select a property value of the vertices to show instead:
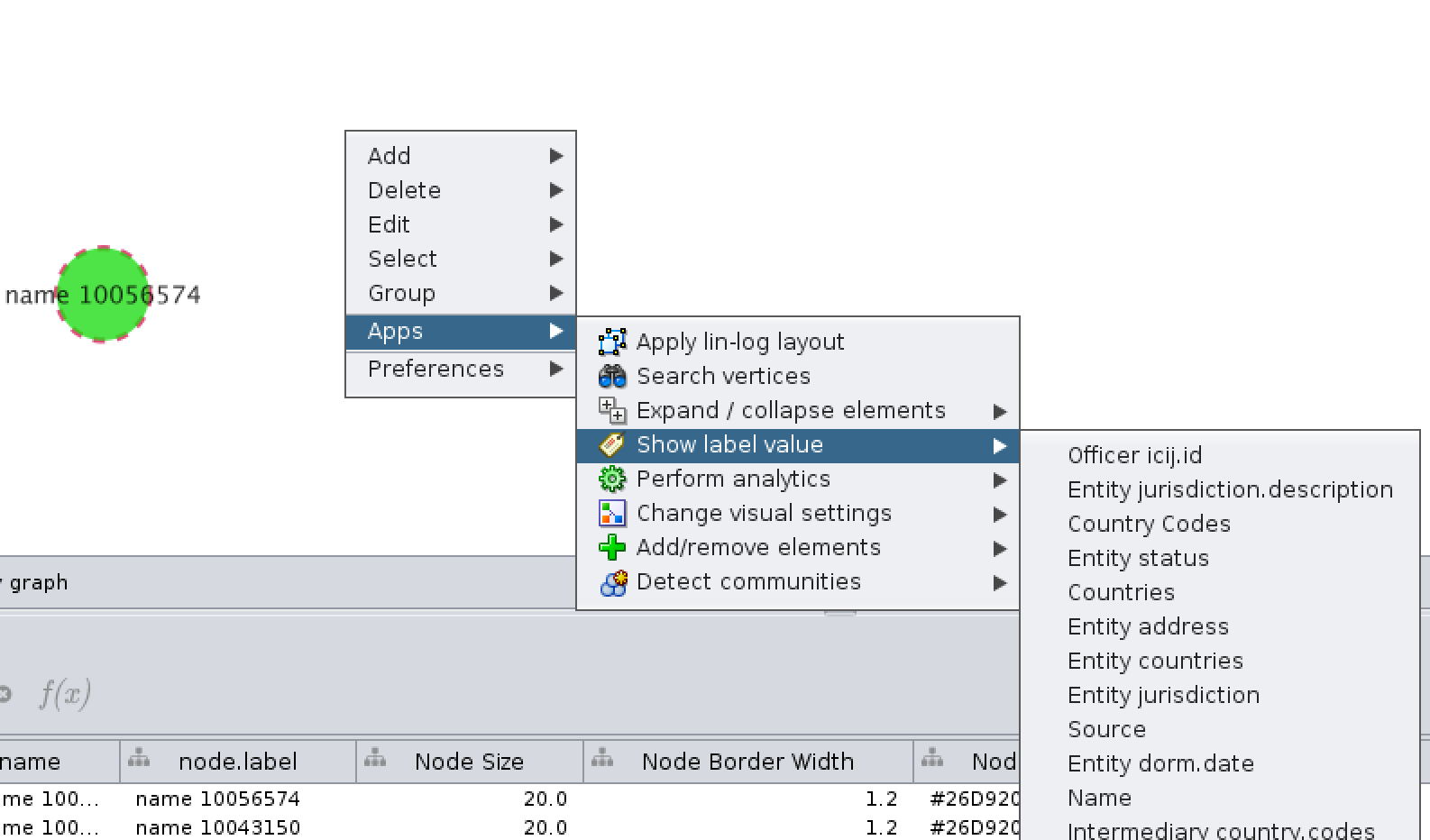
In this example I’ve opted to show the Type of the node:

Now select all the nodes (Ctrl-A, shift-click, or shift-drag a box around them), and from the toolbar select Apps > Property Graph > Expand / collapse elements > Expand selected vertices. This queries the graph database for any directly connected nodes to the nodes that you’ve selected, and shows how each are related (the edge label and direction).
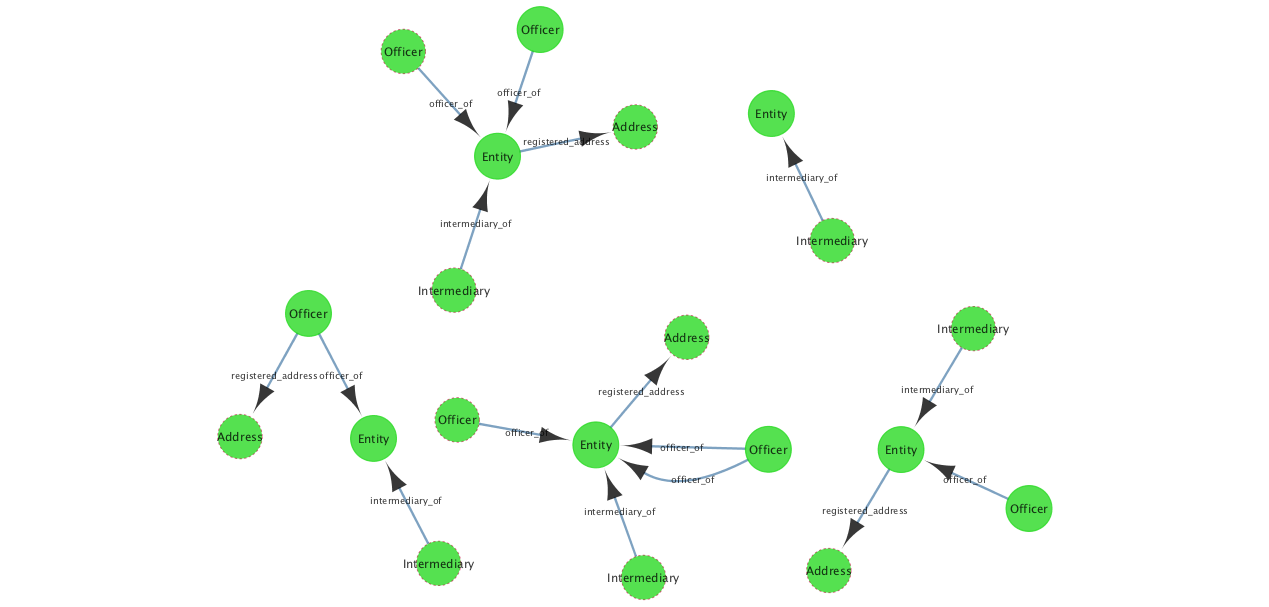
You can repeat this expansion process against one or more nodes to explore the networks further. If you’re using the full dataset you may end up with a lot of nodes if one of your starting ones happened to have a lot of connections (which some of the nodes in the dataset do).

At this point the graph in Cytoscape is a representation of query results returned from the in-memory analysis engine, so you can use the Cytoscape ‘Delete’ function to remove nodes from display without impacting the underlying data. This is useful if an expansion has resulted in hundreds of additional nodes that you’re not interested in pursuing. Use shift-drag to draw a box around them and press Delete on your keyboard, or right-click and select Edit > Cut. Alternatively you can just hide them from the canvas, using the toolbar Select > Hide selected nodes and edges.
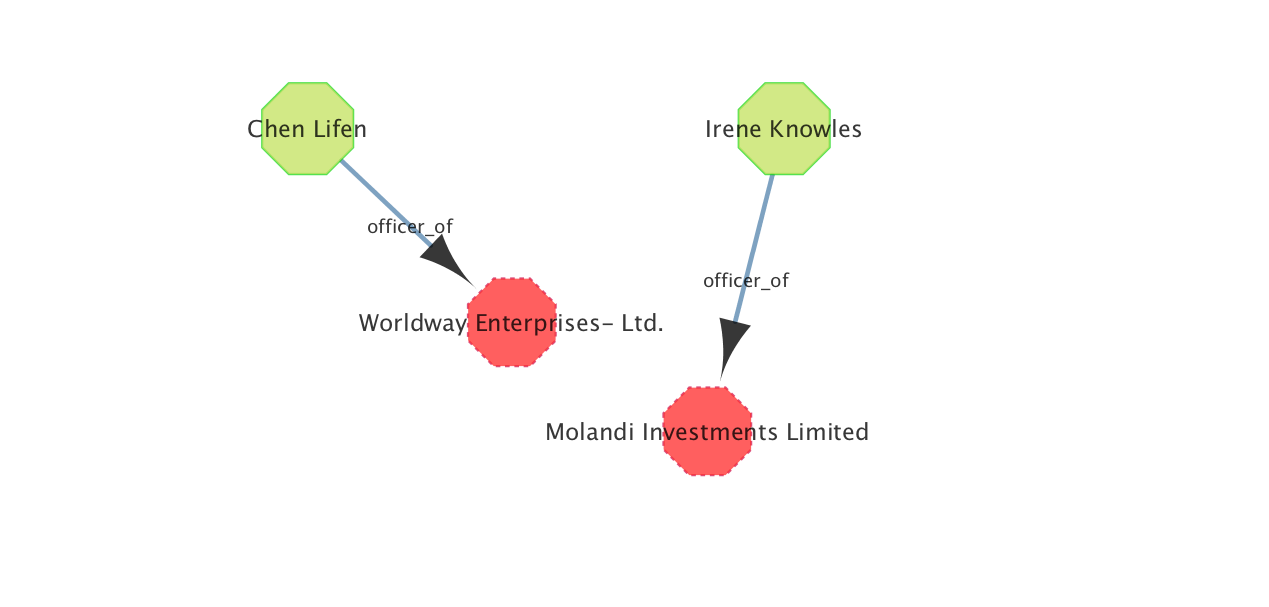
Since each node has a variety of different keys and values, we can aid our comprehension by changing the way that they are rendered based on this. For example, render nodes of a different Type (Address, Entity, Officer, etc) with different colours or shapes. To do this, press the v key, or right-click and select Apps > Change visual settings > Visual Mapping.
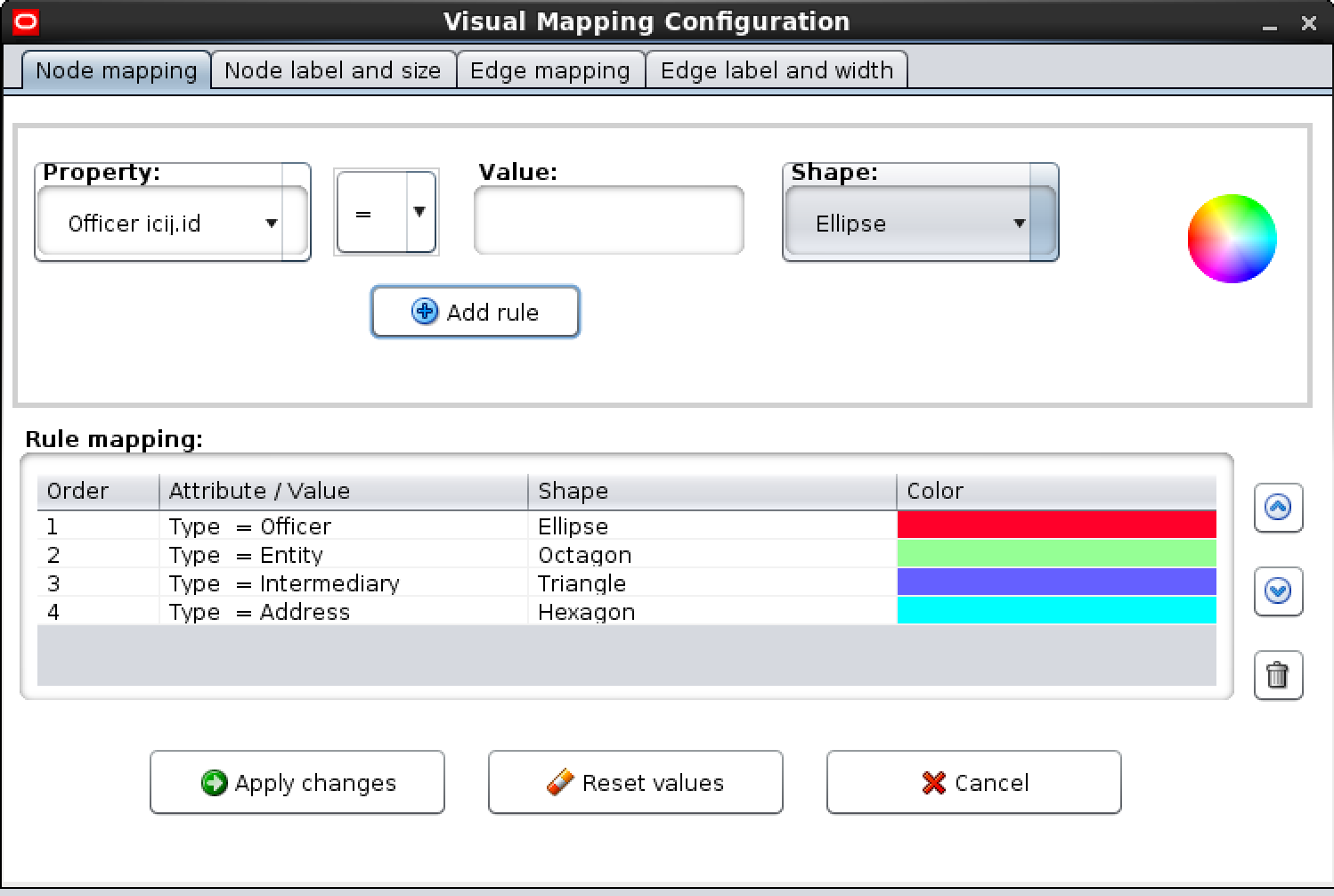
After clicking apply you should see nodes of different types in a different format:
The properties for a selected node can be seen by pressing p, or from the toolbar Apps > Property Graph > Show properties
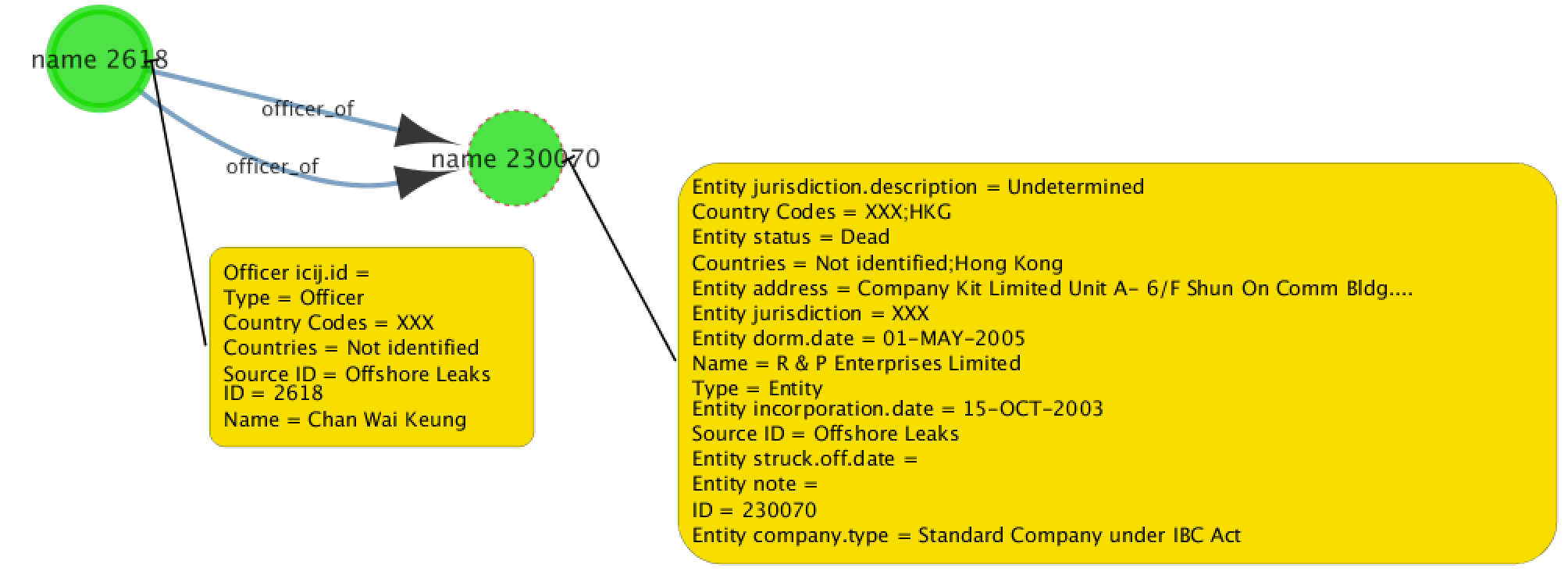
Finally, we can run the community detection algorithm from PGX and apply the results to the existing graph in Cytoscape. This overlays on a starting graph such as this:
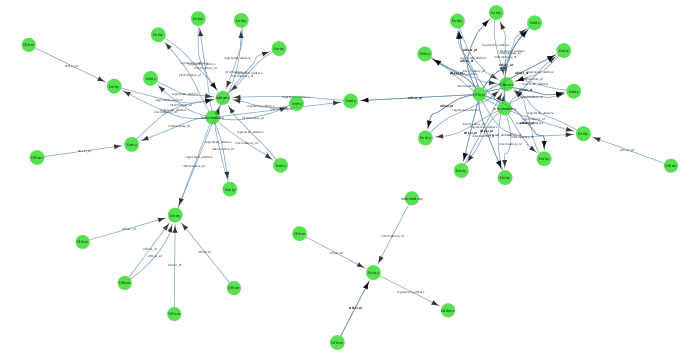
with a visual indication of the communities that exist within the nodes, based on their relationships and distance to other nodes:
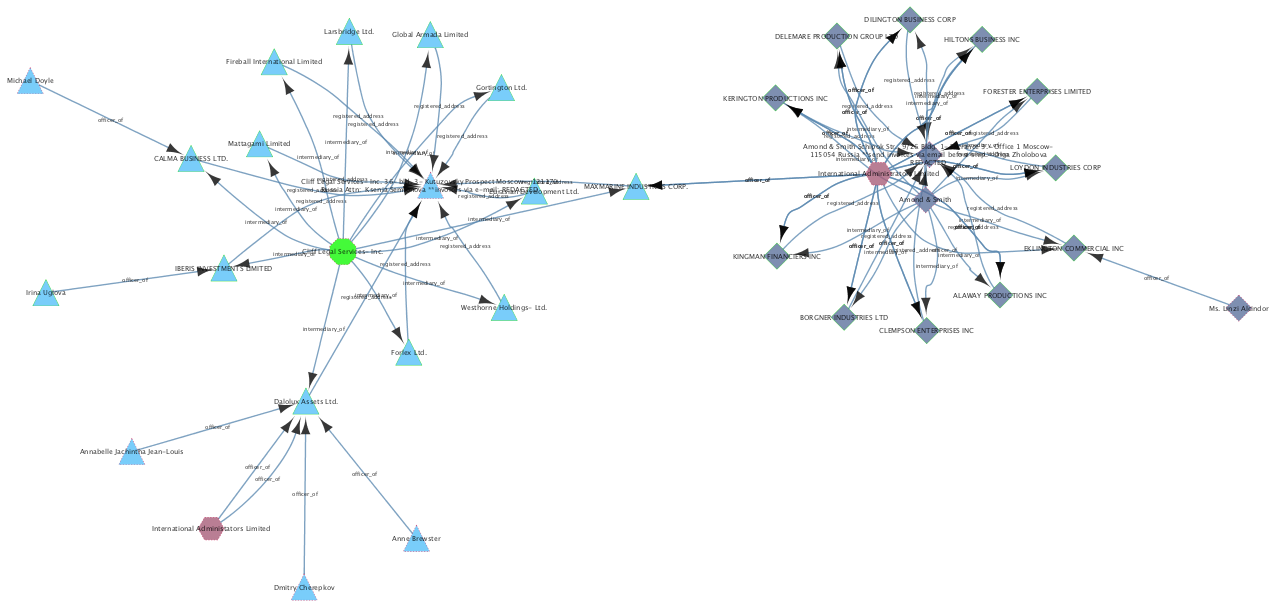
Further Reading