The underlying theme of this blog continues to remain the same as one of my previous blogs i.e. scalable stream processing microservices on Oracle Cloud. But there are significant changes & additions
- Docker: we will package the Kafka Streams based consumer application as a Docker image
- Oracle Container Cloud: our containerized application will run and scale on Oracle Container Cloud
- Service discovery: application is revamped to leverage the service discovery capabilities within Oracle Container Cloud

Technical Components
Here is a quick summary of the technologies used
- Oracle Container Cloud: An enterprise grade platform to compose, deploy and orchestrate Docker containers
- Docker needs no introduction
- Apache Kafka: A scalable, distributed pub-sub message hub
- Kafka Streams: A library for building stream processing applications on top of Apache Kafka
- Jersey: Used to implement REST and SSE services. Uses Grizzly as a (pluggable) runtime/container
- Maven: Used as the standard Java build tool (along with its assembly plugin)
Sample application
By and large, the sample application remains the same and its details can be referred here. Here is a quick summary
- The components: a Kafka broker, a producer application and a consumer (Kafka Streams based) stream processing application
- Changes (as compared to the setup here): the consumer application will now run on Oracle Container Cloud and the application instance discovery semantics (which were earlier Oracle Application Container Cloud specific) have now been implemented on top of Oracle Container Cloud service discovery capability
Architecture
To get an idea of the key concepts, I would recommend going through this section of the High level architecture section of one of the previous blogs . Here is a diagram representing the overall runtime view of the system
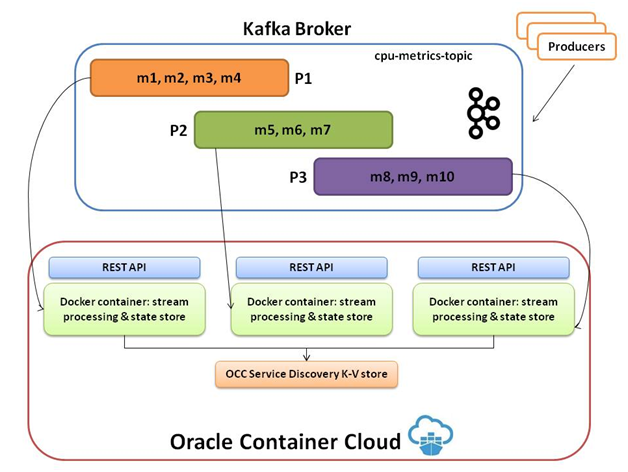
It's key takeaway are as follows
- Oracle Container Cloud will host our containerized stream processing (Kafka consumer) applications
- We will use its elastic scalability features to spin additional containers on-demand to distribute the processing load
- The contents of the topic partitions in Kafka broker (marked as P1, P2, P3) will be distributed among the application instances
Please note that having more application instances than topic partitions will mean that some of your instances will be idle (no processing). It is generally recommended to set the number of topic partitions to a relatively high number (e.g. 50) in order to reap maximum benefit from Kafka
Code
You can refer to this section in the previous blog for code related details (since the bulk of the logic is the same). The logic for service discovery part (which is covered in-depth below) is the major difference (since it relies on Oracle Container Cloud KV store for runtime information). Here is the relevant snippet for the same
/**
\* find yourself in the cloud!
\*
\* [@return](https://forums.oracle.com/ords/apexds/user/return) my port
\*/
public static String getSelfPortForDiscovery() {
String containerID = System.getProperty("CONTAINER\_ID", "container\_id\_not\_found");
//String containerID = Optional.ofNullable(System.getenv("CONTAINER\_ID")).orElse("container\_id\_not\_found");
LOGGER.log(Level.INFO, " containerID {0}", containerID);
String sd\_key\_part = Optional.ofNullable(System.getenv("SELF\_KEY")).orElse("sd\_key\_not\_found");
LOGGER.log(Level.INFO, " sd\_key\_part {0}", sd\_key\_part);
String sd\_key = sd\_key\_part + "/" + containerID;
LOGGER.log(Level.INFO, " SD Key {0}", sd\_key);
String sd\_base\_url = "172.17.0.1:9109/api/kv";
String fullSDUrl = "[http://](http://)" + sd\_base\_url + "/" + sd\_key + "?raw=true";
LOGGER.log(Level.INFO, " fullSDUrl {0}", fullSDUrl);
String hostPort = getRESTClient().target(fullSDUrl)
.request()
.get(String.class);
LOGGER.log(Level.INFO, " hostPort {0}", hostPort);
String port = hostPort.split(":")\[1\];
LOGGER.log(Level.INFO, " Auto port {0}", port);
return port;
}
Kafka setup
On Oracle Compute Cloud
You can refer to part I of the blog for the Apache Kafka related setup on Oracle Compute. The only additional step which needs to be executed is opening of the port on which your Zookeeper process is listening (its 2181 by default) –as this is required by the Kafka Streams library configuration. While executing the steps from section Open Kafka listener port section, ensure that you include the Oracle Compute Cloud configuration for 2181 (in addition to the Kafka broker port 9092)
On Oracle Container Cloud!
You can run a Kafka cluster on Oracle Container Cloud – check out this cool blog post !
The Event Hub Cloud is a new offering which provides Apache Kafka as a managed service in Oracle Cloud
Configuring our application to run on Oracle Container Cloud
Build the application
Execute mvn clean package to build the application JAR
Push to Docker Hub
Create a Docker Hub account if you don't have one already. To build and push the Docker image, execute the below commands
Please ensure that Docker engine is up and running
docker login
docker build –t <registry>/<image_name>:<tag> . e.g. docker build –t abhirockzz/kafka-streams:latest .
docker push <registry>/<image_name>:<tag> e.g. docker push abhirockzz/kafka-streams:latest
Check your Docker Hub account to confirm that the image exists there
Create the Service
To create a new Service, click on New Service in the Services menu

There are multiple ways in which you can configure your service – one of which is the traditional way of filling in each of the attributes in the Service Editor. You can also directly enter the Docker run command or a YAML configuration (similar to docker-compose) and Oracle Container Cloud will automatically populate the Service details. Let’s see the YAML based method in action
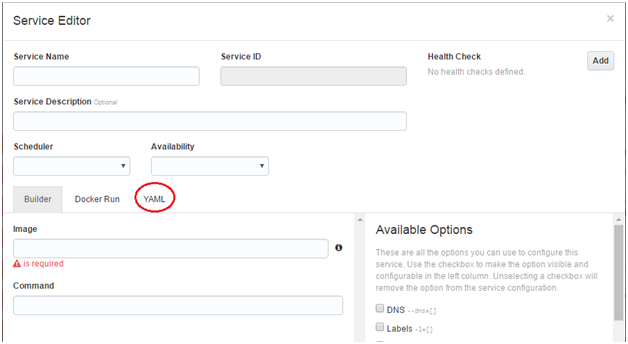
Populate the YAML editor (highlighted above) with the required configuration
version: 2
services:
kstreams:
image: "\<docker hub image e.g. abhirockzz/kafka-streams>"
environment:
- "KAFKA\_BROKER=\<kafka broker host:port e.g. 149.007.42.007:9092>"
- "ZOOKEEPER=\<zookeeper host:port e.g. 149.007.42.007:2181>"
- "SELF\_KEY={{ sd\_deployment\_containers\_path .ServiceID 8080 }}"
- "OCCS\_HOST={{hostip\_for\_interface .HostIPs \\"public\_ip\\"}}"
- "occs:scheduler=random"
ports:
- 8080/tcp
Please make sure that you substitute the host:port for your Kafka broker and Zookeeper server in the yaml configuration file
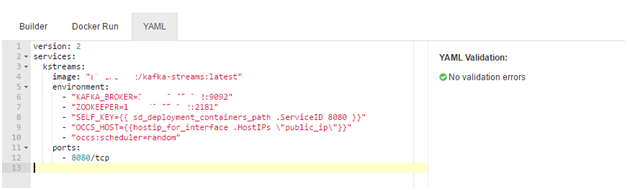
If you switch to the Builder view, notice that all the values have already been populated
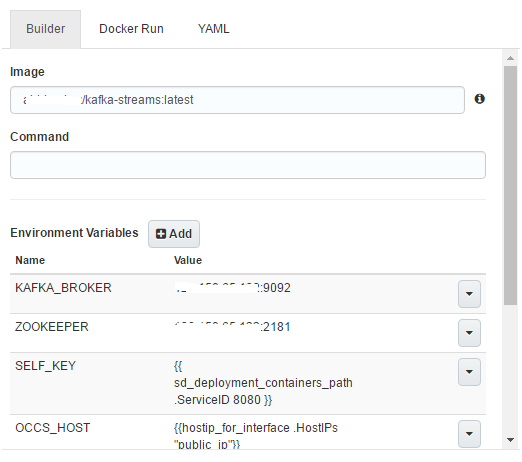
All you need to do is fill out the Service Name and (optionally) choose the Scheduler and Availability properties and click Save to finish the Service creation
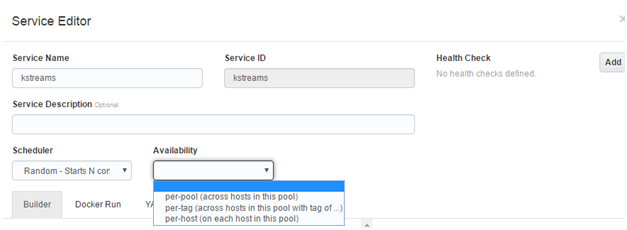
You should see your newly created service in the list of service in the Services menu

YAML configuration details
Here is an overview of the configuration parameters
- Image: Name of the application image on Docker Hub
- Environment variables
-
KAFKA_BROKER: the host and port information to connect to the Kafka broker
-
ZOOKEEPER: the host and port information to connect to the Zookeeper server (for the Kafka broker)
-
SELF_KEY & OCCS_HOST: these are defined as templates functions (more details on this in a moment) and help with dynamic container discovery
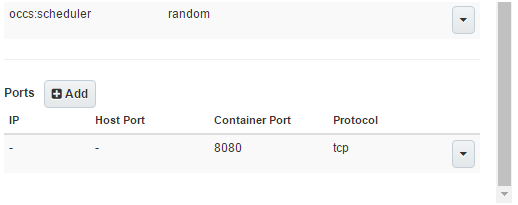
- Ports: Our application is configured to run on port 8080 i.e. this is specified within the code itself. This is not a problem since we have configured a random (auto generated) port on the host (worker node of Oracle Container Cloud) to map to 8080
This is equivalent to using the –P option in docker run command
Template functions and Service discovery
We used the following template functions within the environment variables of our YAML file
|
Environment variable
|
Template function
|
|
|
|
|
SELF_KEY
|
{{ sd_deployment_containers_path .ServiceID 8080 }}
|
|
OCCS_HOST
|
{{hostip_for_interface .HostIPs \"public_ip\"}}
|
What are templates*?
Template arguments provide access to deployment properties related to your services (or stacks) and template functions allow you to utilize them at runtime (in a programmatic fashion). More details in the documentation
Why do we need them?
Within our application, each Kafka Streams consumer application instance needs register to its co-ordinates in the Streams configuration (using the application.server parameter). This in turn allows Kafka Streams to store this as a metadata which can then be used at runtime. Here are some excerpts from the code
Seeding discovery info
Map<String, Object> configurations = new HashMap<>();
String streamsAppServerConfig = GlobalAppState.getInstance().getHostPortInfo().host() + ":"
+ GlobalAppState.getInstance().getHostPortInfo().port();
configurations.put(StreamsConfig.APPLICATION_SERVER_CONFIG, streamsAppServerConfig);
Using the info
Collection<StreamsMetadata> storeMetadata = ks.allMetadataForStore(storeName);
StreamsMetadata metadataForMachine = ks.metadataForKey(storeName, machine, new StringSerializer());
How is this achieved?
For the application.server parameter, we need the host and port of the container instance in Oracle Container Cloud. The OCCS_HOST environment variable is populated automatically by the evaluation of the template function {{hostip_for_interface .HostIPs \"public_ip\"}} – this is the public IP of the Oracle Container Cloud host and takes care of ‘host’ part of the application.server configuration. The port determination needs more work since we have configured port 8080 to be mapped with a random port on Oracle Container Cloud host/worker node. The inbuilt discovery service mechanism within Oracle Container cloud made it possible to implement this.
The internal service discovery database is exposed via a REST API for external clients. But it can be accessed internally (by applications) on 172.17.0.1:9109. It exposes the host and port (of a Docker container) information in a key-value format
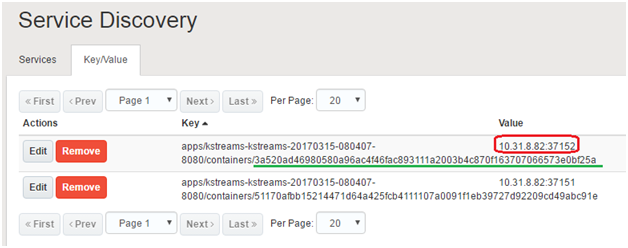
Key points to be noted in the above image
- The part highlighted in red is the value which is the host and port information
- The part highlighted in green is a portion of the key, which is the (dynamic) Docker container ID
- The remaining portion of the key is also dynamic, but can be evaluated with the help of a template function
The trick is to build the above key and then use that to query the discovery service to get the value (host and port details). This is where the SELF_KEY environment variable comes into play. It uses the {{ sd_deployment_containers_path .ServiceID 8080 }} (where 8080 is the exposed and mapped application port) template function which gets evaluated at runtime. This gives us a part of the key i.e. (as per above example) apps/kstreams-kstreams-20170315-080407-8080/containers
The SELF_KEY environment variable is concatenated with the Docker container ID (which is a random UUID) evaluated during container startup within the init.sh script i.e. (in the above example) 3a52….. This completes our key using which we can query the service discovery store.
#!/bin/sh
export CONTAINER_ID=$(cat /proc/self/cgroup | grep 'cpu:/' | sed -r 's/[0-9]+:cpu:.docker.//g')
echo $CONTAINER_ID
java -jar -DCONTAINER_ID=$CONTAINER_ID occ-kafka-streams-1.0.jar
Both SELF_KEY and OCCS_HOST environment variables are used within the internal logic of the Kafka consumer application. The Oracle Container Cloud service discovery store is invoked (using its REST API) at container startup using the complete URL – http://172.17.0.1:9109/api/kv/<SELF_KEY>/<CONTAINER_ID>
See it in action via this code snippet
String containerID = System.getProperty("CONTAINER_ID", "container_id_not_found");
String sd_key_part = Optional.ofNullable(System.getenv("SELF_KEY")).orElse("sd_key_not_found");
String sd_key = sd_key_part + "/" + containerID;
String sd_base_url = "172.17.0.1:9109/api/kv";
String fullSDUrl = "http://" + sd_base_url + "/" + sd_key + "?raw=true";
String hostPort = getRESTClient().target(fullSDUrl).request().get(String.class);
String port = hostPort.split(":")[1];
Initiate Deployment
Start Kafka broker first

Click on the Deploy button to start the deployment. Accept the defaults (for this time) and click Deploy
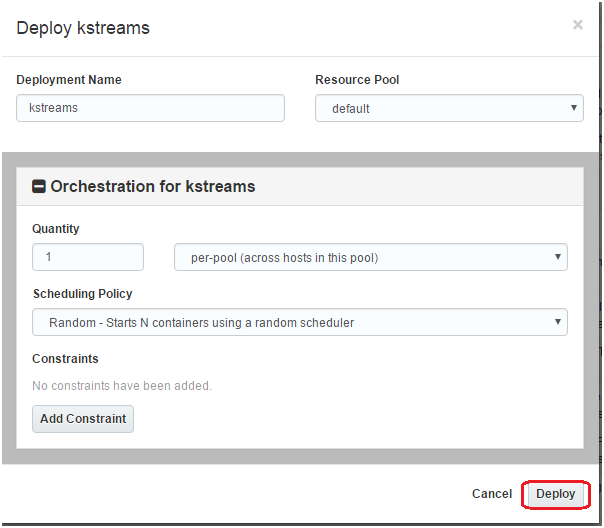
You will be lead into the Deployments screen. Wait for a few seconds for the process to finish
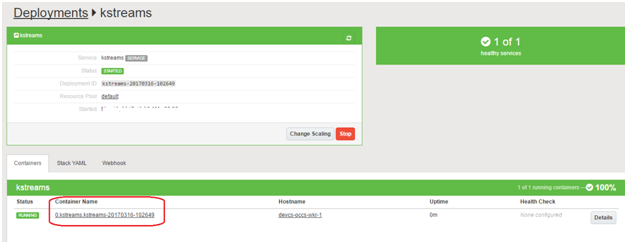
Dive into the container details
Click on the Container Name (highlighted). You will lead to the container specific details page
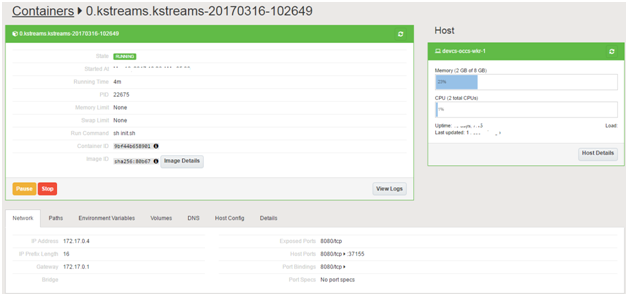
Make a note of the following
Auto bound port
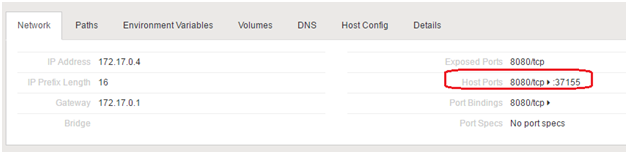
Environment variables (important ones have been highlighted)

Test
Assuming your Kakfa broker is up and running and you have deployed the application successfully, execute the below mentioned steps to test drive your application
Build & start the producer application
mvn clean package //Initiate the maven build
cd target //Browse to the build director
java –jar –DKAFKA_CLUSTER=<kafka broker host:port> kafka-cpu-metrics-producer.jar //Start the application
The producer application will start sending data to the Kakfa broker
Check the statistics
Cumulative moving average of all machines
Allow the producer to run for a 30-40 seconds and then check the current statistics. Issue a HTTP GET request to your consumer application at http://OCCS_HOST:PORT/metrics e.g . http://120.33.42.007:37155/metrics. You’ll see a response payload similar to what’s depicted below
the output below has been truncated for the sake of brevity
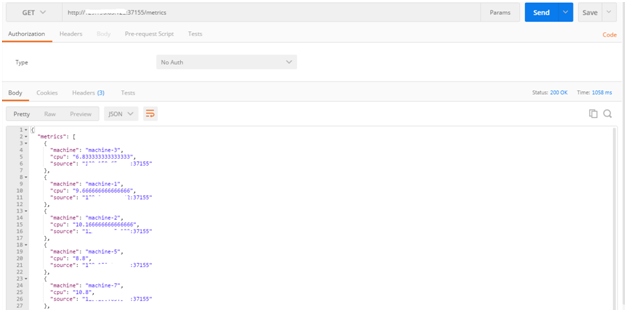
The information in the payload is as following
- cpu: the cumulative average of the CPU usage of a machine
- machine: the machine ID
- source: this has been purposefully added as a diagnostic information to see which node (Docker container in Oracle Container Cloud) is handling the calculation for a specific machine (this is subject to change as your application scales up/down)
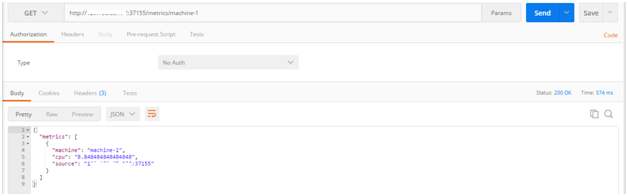
Cumulative moving average of a specific machine
Issue a HTTP GET request to your consumer application at http://OCCS_HOST:PORT/metrics/<machine-ID> e.g. http://120.33.42.007:37155/metrics/machine-1
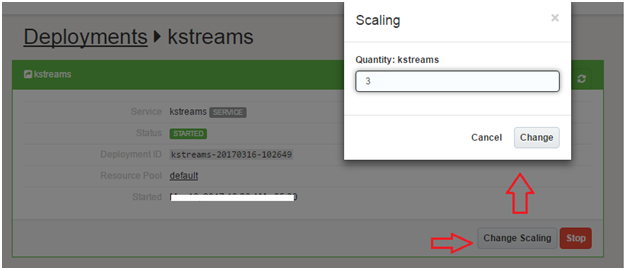
Scale up… and down
Oracle Container Cloud enables your application to remain elastic i.e. scale out or scale in on-demand. The process is simple – let’s see how it works for this application. Choose your deployment from the Deployments menu and click Change Scaling. We are bumping up to 3 instances now
After sometime, you’ll have three containers running separate instances of your Kafka Streams application
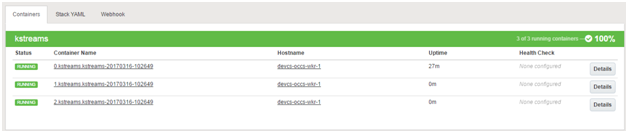
The cpu metrics computation task will now be shared amongst three nodes now. You can check the logs of the old and new container logs to confirm this.
In the old container, Kafka streams will close the existing processing tasks in order to re-distribute them to the new nodes. On checking the logs, you will see something similar to the below output

In the new containers, you will see Processor Initialized output, as a result of tasks being handed to these nodes. Now you can check the metrics using any of the three instances (check the auto bound port for the new containers). You can spot the exact node which has calculated the metric (notice the different port number). See snippet below

Scale down: You can scale down the number of instances using the same set of step and Kafka Streams will take care re-balancing the tasks among the remaining nodes
Note on Dynamic load balancing
In a production setup, one would want to load balance the consumer microservices by using haproxy, ngnix etc. (in this example one had to inspect each application instance by using the auto bound port information). This might be covered in a future blog post. Oracle Container Cloud provides you the ability to easily build such a coordinated set of services using Stacks and ships with some example stacks for reference purposes
That’s all for this blog post.... Cheers!
The views expressed in this post are my own and do not necessarily reflect the views of Oracle.