Background:
Our system has a dumping table, multiple threads simultaneously inserts 100k records to this table -> lets call it EVENT_DUMP table
we want to de-duplicate these events and insert into another table -> lets call it PROBABLE_EVENTS table. Also, at the same time delete these records from EVENT_DUMP table
Other Details:
EVENT_DUMP can have approximately 7-8M records
But distinct records in EVENT_DUMP are only 1K
There can be already existing duplicate records in PROBABLE_EVENTS
existing records in PROBABLE_EVENTS table can be 15K
Question is:
What is the best approach
to de-duplicate records from EVENT_DUMP table ---> use E_KEY as a unique identifier of a record
insert (that do not already exits) in PROBABLE_EVENTS table
Delete these records from EVENT_DUMP table
ALL IN ONE TRANSACTION
What I have tried so far
Using Triggers, but I found this post saying triggers are slow http://rwijk.blogspot.com/2007/09/database-triggers-are-evil.html
Using SELECT INTO within Procedure, but again this link mentions - load only small datasets into memory: https://docs.oracle.com/cd/B14117_01/appdev.101/b10807/13_elems045.htm
But I could not come to a complete solution yet, that maintains integrity and is efficient.
Sharing Scripts for TEST DATA:
CREATE TABLE EVENT_DUMP
(
Version SMALLINT NOT NULL,
E_KEY VARCHAR(512) NOT NULL,
ENTITY_ID VARCHAR(255) NOT NULL,
IDENTIFIER VARCHAR (4000),
NAME VARCHAR(4000) NOT NULL,
DESCRIPTION VARCHAR(4000),
CONFIG CLOB NOT NULL
);
CREATE TABLE PROBABLE_EVENTS (
Version SMALLINT NOT NULL,
E_KEY VARCHAR(512) NOT NULL,
ENTITY_ID VARCHAR(255) NOT NULL,
IDENTIFIER VARCHAR (4000),
NAME VARCHAR(4000) NOT NULL,
DESCRIPTION VARCHAR(4000),
CONFIG CLOB,
ARCHIVAL_STATUS VARCHAR(16),
ARCHIVAL_RETRY_COUNT SMALLINT,
ARCHIVAL_ATTEMPT_TS TIMESTAMP
);
-- TO GENERATE HUGE TEST DATA
-- two loops are executed:: 20*4
-- creates 8,000,000 records in EVENT_DUMP and creates 40 records in PROBABLE_EVENTS
begin
for cnt in 1..20 loop
for n IN 1..4 loop
-- create a few records in
if mod(n,2) = 0 THEN
MERGE INTO PROBABLE_EVENTS USING DUAL ON (E_KEY = n)
WHEN NOT MATCHED THEN
INSERT (Version, E_KEY, ENTITY_ID, IDENTIFIER, NAME, DESCRIPTION, CONFIG, ARCHIVAL_STATUS, ARCHIVAL_RETRY_COUNT)
values( 2, n, 'entityID-' || n, 'some event identifier', 'name', 'description', '{"config":"some value"}', 'Pending', 0 );
end if;
-- create an entry in EVENT_DUMP
insert into EVENT_DUMP(Version, E_KEY, ENTITY_ID, IDENTIFIER, NAME, DESCRIPTION, CONFIG)
values( 2, n, 'entityID-' || n, 'some event identifier', 'name', 'description', '{"config":"some value"}') ;
end loop;
end loop;
end;
Data generated by the above script:
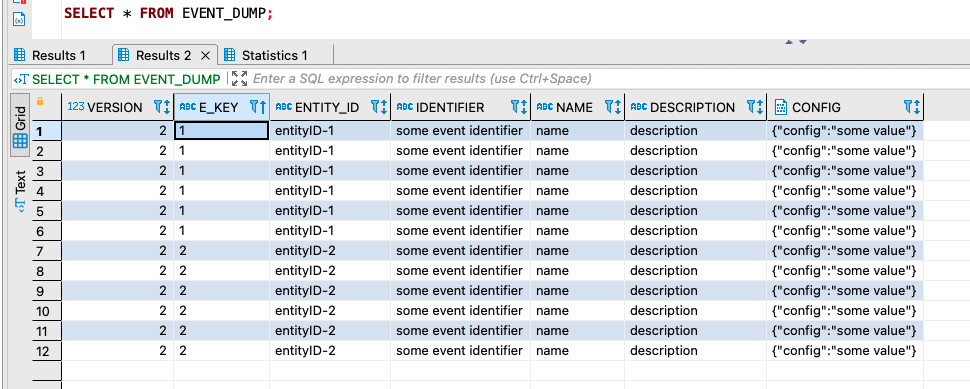
 Expected Output (for the sample data) after running the solution:
Expected Output (for the sample data) after running the solution:
No records in EVENT_DUMP table
2 records in PROBABLE_EVENTS table

FYI: We found a solution for Postrges DB, sharing for reference:
with deleted_rows as (
delete
from
EVENT_DUMP
where ctid in ( select ctid from EVENT_DUMP limit 1000000 )
returning *
)
insert
into
PROBABLE_EVENTS(version, e_key, ENTITY_ID, IDENTIFIER, NAME, DESCRIPTION, CONFIG )
select
distinct on
(dr.e_key)
dr.Version, dr.e_key, dr.ENTITY_ID, dr.IDENTIFIER, dr.NAME, dr.DESCRIPTION, dr.CONFIG
from
deleted_rows dr
left join PROBABLE_EVENTS pe on
dr.e_key = pe.e_key
where
pe.e_key is null;