This is the first of a two-part blog series. It leverages the Oracle Cloud platform (in concert with some widely used open source technologies) to demonstrate message based, loosely coupled and asynchronous interaction between microservices with the help of a sample application. It deals with
- Development of individual microservices
- Using asynchronous messaging for loosely coupled interactions
- Setup & deployment on respective Oracle Cloud services
The second part is available here

Technical components
Oracle Cloud
The following Oracle Cloud services have been leveraged
|
Oracle Cloud Service
|
Description
|
|
|
|
|
Application Container Cloud
|
Serves as a scalable platform for deploying our Java SE microservices
|
|
Compute Cloud
|
Hosts the Kafka cluster (broker)
|
|
|
|
Open source technologies
The following open source components were used to build the sample application
|
Component
|
Description
|
|
|
|
|
Apache Kafka
|
A scalable, pub-sub message hub
|
|
Jersey
|
Used to implement REST and SSE services. Uses Grizzly as a (pluggable) runtime/container
|
|
Maven
|
Used as the standard Java build tool (along with its assembly plugin)
|
Messaging in Microservices
A microservice based system comprises of multiple applications (services) which typically focus on a specialized aspect (business scenario) within the overall system. It’s possible for these individual services to function independently without any interaction what so ever, but that’s rarely the case. They cannot function in isolation and need to communicate with each other to get the job done. There are multiple strategies used to implement inter-microservice communication and they are often categorized under buckets such as synchronous vs asynchronous styles, choreography vs orchestration, REST (HTTP) vs messaging etc.
About the sample application
Architecture
The use case chosen for the sample application in this example is a simple one. It works with randomly generated data (the producer microservice) which is received by a another entity (the consumer microservice) and ultimately made available using the browser for the user to see it in real time
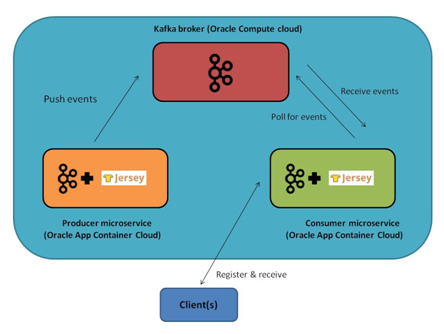
A highly available setup has not been taken into account in this post. What we have is a single Kafka node i.e. there is just one server in the Kafka cluster and both the Producer and Consumer microservices are deployed in Application Container Cloud (both have a single instance each)
Let’s look at the individual components depicted in the above diagram
Apache Kafka
Apache Kafka is popularly referred to as a ‘_messaging system or a streaming platform implemented as a distributed commit log_’. It would be nice to have a simpler explanation
- Basic: Kafka is a publish-subscribe based messaging system written in Scala (runs on the JVM) where publishers write to topics and consumers poll these topics to get data
- Distributed: the parts (broker, publisher and consumer) are designed to be horizontally scalable
- Master slave architecture: data in topics is distributed amongst multiple nodes in a cluster (based on the replication factor). Only one node serves as a master for a specific piece of data while 0 or more nodes can contain copies of that data i.e. act as followers
- Partitions: Topics are further divided into partitions. Each partition basically acts as a commit log where the data (key-value pairs) is stored. The data is immutable, has strict ordering (offset is assigned for each data entry), is persisted and retained to disk (based on configuration)
- Fitment: Kafka is suitable for handling high volume, high velocity, real time streaming data
- Not JMS: Similar yet different from JMS. It does not implement the JMS specification, neither is it meant to serve as a drop in replacement for a JMS based solution
The Kafka broker is nothing but a Kafka server process (node). Multiple such nodes can form a cluster which act as a distributed, fault-tolerant and horizontally scalable message hub.
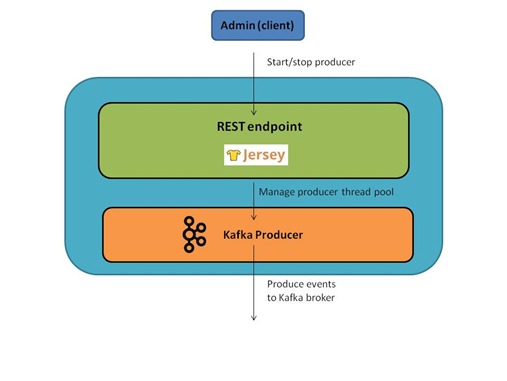
Producer Microservice
It leverages the Kafka Java API and Jersey (the JAX-RS implementation). This microservice publishes sample set of events at a rapid pace since the goal is to showcase a real time data pub-sub pipeline.
Sample data
Data emitted by the producer is modeled around metrics. In this example it’s the CPU usage of a particular machine and can be thought of as simple key-value pairs (name, % usage etc.). Here is what it looks like (ignore the Partition attribute info)
: Partition 0
event: machine-2
id: 19
data: 14%
: Partition 1
event: machine-1
id: 20
data: 5%
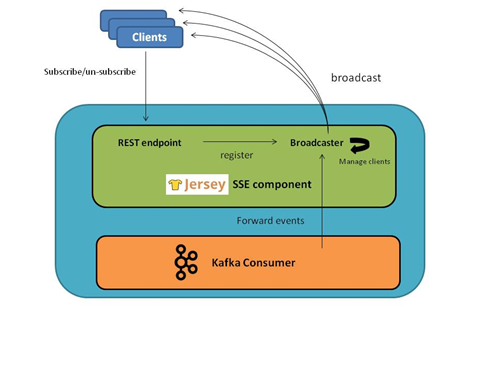
Consumer Microservice
This is the 2nd microservice in our system. Just like the Producer, it makes use of Jersey as well as the Kafka Java (consumer) API. Another noteworthy Jersey component which is used is the Server Sent Events module which helps implement subscribe-and-broadcast semantics required by our sample application (more on this later)
Both the microservices are deployed as separate applications on the Application Container Cloud platform and can be managed and scaled independently
Setting up Apache Kafka on Oracle Compute Cloud
You have a couple of options for setting up Apache Kafka on Oracle Compute Cloud (IaaS)
Bootstrap a Kafka instance using Oracle Cloud Marketplace
Use the Bitnami image for Apache Kafka from the marketplace (for detailed documentation, please refer this link)
Use a VM on Oracle Compute Cloud
Start by provisioning a Compute Cloud VM on the operating system of your choice – this documentation provides an excellent starting point
Enable SSH access to VM
To execute any of the configurations, you first need to enable SSH access (create security policies/rules) to your Oracle Compute Cloud VM. Please find the instructions for Oracle Linux and Oracle Solaris based VMs respectively

Install Kafka on the VM
This section assumes Oracle Enterprise Linux based VM
Here are the commands
sudo yum install java-1.8.0-openjdk
sudo yum install wget
mkdir -p ~/kafka-download
wget "http://redrockdigimark.com/apachemirror/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz" -O ~/kafka-download/kafka-binary.tgz
mkdir -p ~/kafka-install && cd ~/kafka-install
tar -xvzf ~/kafka-download/kafka-binary.tgz --strip 1
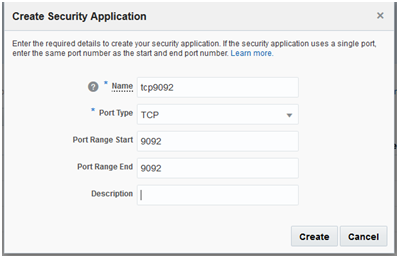
Open Kafka listener port
You need to allow access to Kafka broker service (on port 9092 in this case) for the microservices deployed on Oracle Application Container Cloud. This documentation provides a great reference in the form of a use case. Create a Security Application to specify the protocol and the respective port – detailed documentation here
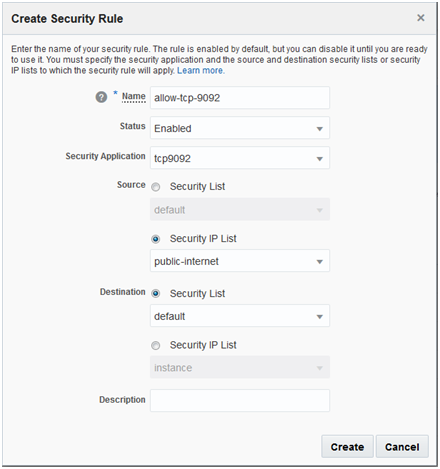
Reference the Security Application created in the previous step to configure the Security Rule. This will allow traffic from public internet (as defined in the rule) onto port 9092 (as per Security Application configuration). Please refer to the following documentation for details
You will end up with a configuration similar to what's depicted below

Configure Kafka broker
Make sure that you edit the below mentioned attributes in Kafka server properties (<KAFKA_INSTALL>/config/server.properties) as per your Compute Cloud environment
Public DNS of your Compute Cloud instance: if the public IP is 140.44.88.200, then the public DNS will be oc-140-44-88-200.compute.oraclecloud.com
| Attribute | Value |
| | |
| listeners |
PLAINTEXT://<oracle-compute-private-IP>:<kafka-listen-port>
e.g. PLAINTEXT://10.190.210.199:9092 |
| advertised.listeners |
PLAINTEXT://<oracle-compute-public-DNS>:<kafka-listen-port>
e.g. PLAINTEXT://oc-140-44-88-200.compute.oraclecloud.com:9092 |
Here is a snapshot of the server.properties file

Start Zookeeper by executing KAFKA_INSTALL/bin/zookeeper-server-start.sh config/zookeeper.properties
Start Kafka Broker by executing KAFKA_INSTALL/bin/kafka-server-start.sh config/server.properties

Do not start Kafka broker before Zookeeper
High level solution overview
Event flow/sequence
Let’s look at how these components work together to support the entire use case
The producer pushes events into the Kafka broker
On the consumer end
- The application polls Kafka broker for the data (yes, the poll/pull model is used in Kafka as opposed to the more commonly seen push model)
- A client (browser/http client) subscribes for events by simply sending a HTTP GET to a specific URL (e.g. https://<acc-app-url>/metrics). This is one time subscribe after which the client will get events as they are produced within the application and it can choose to disconnect any time
Asynchronous, loosely coupled: The metrics data is produced by the consumer. One consumer makes it available as a real time feed for browser based clients, but there can be multiple such consuming entities which can implement a different set of business logic around the same data set e.g. push the metrics data to a persistent data store for processing/analysis etc.
More on Server Sent Events (SSE)
SSE is the middle ground between HTTP and WebSocket. The client sends the request, and once established, the connection is kept open and it can continue to receive data from server
- This is more efficient compared to HTTP request-response paradigm for every single request i.e. polling the server can be avoided
- It’s not the same as WebSocket which are full duplex in nature i.e. the client and server can exchange messages anytime after connection is established. In SSE, the client only sends a request once
This model suits our sample application since the client just needs to connect and wait for data to arrive (it does not need to interact with the server after the initial subscription)
Other noteworthy points
- SSE is a formal W3C specification
- It defines a specific media type for the data
- Has JavaScript implementation in most browsers
Scalability
It’s worth noting that, all the parts of this system are stateless and horizontally scalable in order to maintain high throughput and performance. The second part of this blog will dive deeper into the scalability aspects and see how Application Container Cloud makes it easy to achieve this
Code
This section will briefly cover the code used for this sample and highlight the important points (for both our microservices)
Producer microservice
It consists of a cohesive bunch of classes which handle application bootstrapping, event production etc.
|
Class
|
Details
|
|
|
|
|
ProducerBootstrap.java
|
Entry point for the application. Kicks off Grizzly container
|
|
Producer.java
|
Runs in a dedicated thread. Contains core logic for producing event.
|
|
ProducerManagerResource.java
|
Exposes a HTTP(s) endpoint to start/stops the producer process
|
|
ProducerLifecycleManager.java
|
Implements logic to manage Producer thread using ExecutorService. Used internally by ProducerManagerResource
|
ProducerBootstrap.java
public class ProducerBootstrap {
private static final Logger LOGGER = Logger.getLogger(ProducerBootstrap.class.getName());
private static void bootstrap() throws IOException {
String hostname = Optional.ofNullable(System.getenv("HOSTNAME")).orElse("localhost");
String port = Optional.ofNullable(System.getenv("PORT")).orElse("8080");
URI baseUri = UriBuilder.fromUri("[http://](http://community.oracle.com/)" + hostname + "/").port(Integer.parseInt(port)).build();
ResourceConfig config = new ResourceConfig(ProducerManagerResource.class);
HttpServer server = GrizzlyHttpServerFactory.createHttpServer(baseUri, config);
LOGGER.log(Level.INFO, "Application accessible at {0}", baseUri.toString());
//gracefully exit Grizzly services when app is shut down
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
LOGGER.log(Level.INFO, "Exiting......");
try {
server.shutdownNow();
LOGGER.log(Level.INFO, "REST services stopped");
ProducerLifecycleManager.getInstance().stop();
LOGGER.log(Level.INFO, "Kafka producer thread stopped");
} catch (Exception ex) {
//log & continue....
LOGGER.log(Level.SEVERE, ex, ex::getMessage);
}
}
}));
server.start();
}
public static void main(String\[\] args) throws Exception {
bootstrap();
}
}
Producer.java
public class Producer implements Runnable {
private static final Logger LOGGER = Logger.getLogger(Producer.class.getName());
private static final String TOPIC\_NAME = "cpu-metrics-topic";
private KafkaProducer\<String, String> kafkaProducer = null;
private final String KAFKA\_CLUSTER\_ENV\_VAR\_NAME = "KAFKA\_CLUSTER";
public Producer() {
LOGGER.log(Level.INFO, "Kafka Producer running in thread {0}", Thread.currentThread().getName());
Properties kafkaProps = new Properties();
String defaultClusterValue = "localhost";
String kafkaCluster = System.getenv().getOrDefault(KAFKA\_CLUSTER\_ENV\_VAR\_NAME, defaultClusterValue);
LOGGER.log(Level.INFO, "Kafka cluster {0}", kafkaCluster);
kafkaProps.put(ProducerConfig.BOOTSTRAP\_SERVERS\_CONFIG, kafkaCluster);
kafkaProps.put(ProducerConfig.KEY\_SERIALIZER\_CLASS\_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put(ProducerConfig.VALUE\_SERIALIZER\_CLASS\_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put(ProducerConfig.ACKS\_CONFIG, "0");
this.kafkaProducer = new KafkaProducer\<>(kafkaProps);
}
@Override
public void run() {
try {
produce();
} catch (Exception e) {
LOGGER.log(Level.SEVERE, e.getMessage(), e);
}
}
/\*\*
\* produce messages
\*
\* [@throws](https://forums.oracle.com/ords/apexds/user/throws) Exception
\*/
private void produce() throws Exception {
ProducerRecord\<String, String> record = null;
try {
Random rnd = new Random();
while (true) {
String key = "machine-" + rnd.nextInt(5);
String value = String.valueOf(rnd.nextInt(20));
record = new ProducerRecord\<>(TOPIC\_NAME, key, value);
kafkaProducer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata rm, Exception excptn) {
if (excptn != null) {
LOGGER.log(Level.WARNING, "Error sending message with key {0}\\n{1}", new Object\[\]{key, excptn.getMessage()});
} else {
LOGGER.log(Level.INFO, "Partition for key {0} is {1}", new Object\[\]{key, rm.partition()});
}
}
});
/\*\*
\* wait before sending next message. this has been done on
\* purpose
\*/
Thread.sleep(1000);
}
} catch (Exception e) {
LOGGER.log(Level.SEVERE, "Producer thread was interrupted");
} finally {
kafkaProducer.close();
LOGGER.log(Level.INFO, "Producer closed");
}
}
}
ProducerLifecycleManager.java
public final class ProducerLifecycleManager {
private static final Logger LOGGER = Logger.getLogger(ProducerLifecycleManager.class.getName());
private ExecutorService es;
private static ProducerLifecycleManager INSTANCE = null;
private final AtomicBoolean RUNNING = new AtomicBoolean(false);
private ProducerLifecycleManager() {
es = Executors.newSingleThreadExecutor();
}
public static ProducerLifecycleManager getInstance(){
if(INSTANCE == null){
INSTANCE = new ProducerLifecycleManager();
}
return INSTANCE;
}
public void start() throws Exception{
if(RUNNING.get()){
throw new IllegalStateException("Service is already running");
}
if(es.isShutdown()){
es = Executors.newSingleThreadExecutor();
System.out.println("Reinit executor service");
}
es.execute(new Producer());
LOGGER.info("started producer thread");
RUNNING.set(true);
}
public void stop() throws Exception{
if(!RUNNING.get()){
throw new IllegalStateException("Service is NOT running. Cannot stop");
}
es.shutdownNow();
LOGGER.info("stopped producer thread");
RUNNING.set(false);
}
}
ProducerManagerResource.java
@Path("producer")
public class ProducerManagerResource {
/\*\*
\* start the Kafka Producer service
\* [@return](https://forums.oracle.com/ords/apexds/user/return) 200 OK for success, 500 in case of issues
\*/
@GET
public Response start() {
Response r = null;
try {
ProducerLifecycleManager.getInstance().start();
r = Response.ok("Kafka Producer started")
.build();
} catch (Exception ex) {
Logger.getLogger(ProducerManagerResource.class.getName()).log(Level.SEVERE, null, ex);
r = Response.serverError().build();
}
return r;
}
/\*\*
\* stop consumer
\* [@return](https://forums.oracle.com/ords/apexds/user/return) 200 OK for success, 500 in case of issues
\*/
@DELETE
public Response stop() {
Response r = null;
try {
ProducerLifecycleManager.getInstance().stop();
r = Response.ok("Kafka Producer stopped")
.build();
} catch (Exception ex) {
Logger.getLogger(ProducerManagerResource.class.getName()).log(Level.SEVERE, null, ex);
r = Response.serverError().build();
}
return r;
}
}
Consumer microservice
|
Class
|
Details
|
|
|
|
|
ConsumerBootstrap.java
|
Entry point for the application. Kicks off Grizzly container and triggers the Consumer process
|
|
Consumer.java
|
Runs in a dedicated thread. Contains core logic for consuming events
|
|
ConsumerEventResource.java
|
Exposes a HTTP(s) endpoint for end users to consume events
|
|
EventCoordinator.java
|
Wrapper around Jersey SSEBroadcaster to implement event subscription & broadcasting. Used internally by ConsumerEventResource
|
Consumer.java
public class Consumer implements Runnable {
private static final Logger LOGGER = Logger.getLogger(Consumer.class.getName());
private static final String TOPIC\_NAME = "cpu-metrics-topic";
private static final String CONSUMER\_GROUP = "cpu-metrics-group";
private final AtomicBoolean CONSUMER\_STOPPED = new AtomicBoolean(false);
private KafkaConsumer\<String, String> consumer = null;
private final String KAFKA\_CLUSTER\_ENV\_VAR\_NAME = "KAFKA\_CLUSTER";
/\*\*
\* c'tor
\*/
public Consumer() {
Properties kafkaProps = new Properties();
LOGGER.log(Level.INFO, "Kafka Consumer running in thread {0}", Thread.currentThread().getName());
String defaultClusterValue = "localhost";
String kafkaCluster = System.getenv().getOrDefault(KAFKA\_CLUSTER\_ENV\_VAR\_NAME, defaultClusterValue);
LOGGER.log(Level.INFO, "Kafka cluster {0}", kafkaCluster);
kafkaProps.put(ProducerConfig.BOOTSTRAP\_SERVERS\_CONFIG, kafkaCluster);
kafkaProps.put(ConsumerConfig.GROUP\_ID\_CONFIG, CONSUMER\_GROUP);
kafkaProps.put(ConsumerConfig.KEY\_DESERIALIZER\_CLASS\_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
kafkaProps.put(ConsumerConfig.VALUE\_DESERIALIZER\_CLASS\_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer\<>(kafkaProps);
}
/\*\*
\* invoke this to stop this consumer from a different thread
\*/
public void stop() {
if(CONSUMER\_STOPPED.get()){
throw new IllegalStateException("Kafka consumer service thread is not running");
}
LOGGER.log(Level.INFO, "signalling shut down for consumer");
if (consumer != null) {
CONSUMER\_STOPPED.set(true);
consumer.wakeup();
}
}
@Override
public void run() {
consume();
}
/\*\*
\* poll the topic and invoke broadcast service to send information to connected SSE clients
\*/
private void consume() {
consumer.subscribe(Arrays.asList(TOPIC\_NAME));
LOGGER.log(Level.INFO, "Subcribed to: {0}", TOPIC\_NAME);
try {
while (!CONSUMER\_STOPPED.get()) {
LOGGER.log(Level.INFO, "Polling broker");
ConsumerRecords\<String, String> msg = consumer.poll(1000);
for (ConsumerRecord\<String, String> record : msg) {
EventCoordinator.getInstance().broadcast(record);
}
}
LOGGER.log(Level.INFO, "Poll loop interrupted");
} catch (Exception e) {
//ignored
} finally {
consumer.close();
LOGGER.log(Level.INFO, "consumer shut down complete");
}
}
}
ConsumerBootstrap.java
public final class ConsumerBootstrap {
private static final Logger LOGGER = Logger.getLogger(ConsumerBootstrap.class.getName());
/\*\*
\* Start Grizzly services and Kafka consumer thread
\*
\* [@throws](https://forums.oracle.com/ords/apexds/user/throws) IOException
\*/
private static void bootstrap() throws IOException {
String hostname = Optional.ofNullable(System.getenv("HOSTNAME")).orElse("localhost");
String port = Optional.ofNullable(System.getenv("PORT")).orElse("8081");
URI baseUri = UriBuilder.fromUri("[http://](http://community.oracle.com/)" + hostname + "/").port(Integer.parseInt(port)).build();
ResourceConfig config = new ResourceConfig(ConsumerEventResource.class, SseFeature.class);
HttpServer server = GrizzlyHttpServerFactory.createHttpServer(baseUri, config);
Logger.getLogger(ConsumerBootstrap.class.getName()).log(Level.INFO, "Application accessible at {0}", baseUri.toString());
Consumer kafkaConsumer = new Consumer(); //will initiate connection to Kafka broker
//gracefully exit Grizzly services and close Kafka consumer when app is shut down
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
LOGGER.log(Level.INFO, "Exiting......");
try {
server.shutdownNow();
LOGGER.log(Level.INFO, "Grizzly services stopped");
kafkaConsumer.stop();
LOGGER.log(Level.INFO, "Kafka consumer thread stopped");
} catch (Exception ex) {
//log & continue....
LOGGER.log(Level.SEVERE, ex, ex::getMessage);
}
}
}));
server.start();
new Thread(kafkaConsumer).start();
}
/\*\*
\* Entry point
\*
\* [@param](https://forums.oracle.com/ords/apexds/user/param) args
\* [@throws](https://forums.oracle.com/ords/apexds/user/throws) Exception
\*/
public static void main(String\[\] args) throws Exception {
bootstrap();
}
}
ConsumerEventResource.java
/**
* This class allows clients to subscribe to events by
* sending a HTTP GET to host:port/events. The server will keep the connection open
* and send events (as and when received) unless closed by the client
*
*/
@Path("metrics")
public final class ConsumerEventResource {
//private static final Logger LOGGER = Logger.getLogger(ConsumerEventResource.class.getName());
/\*\*
\* Call me to subscribe to events. Delegates to EventCoordinator
\*
\* [@return](https://forums.oracle.com/ords/apexds/user/return) EventOutput which will keep the connection open
\*/
@GET
@Produces(SseFeature.SERVER\_SENT\_EVENTS)
public EventOutput subscribe() {
return EventCoordinator.getInstance().subscribe();
}
}
EventCoordinator.java
public final class EventCoordinator {
private static final Logger LOGGER = Logger.getLogger(EventCoordinator.class.getName());
private EventCoordinator() {
}
/\*\*
\* SseBroadcaster is used because
\* 1. it tracks client stats
\* 2. automatically dispose server resources if clients disconnect
\* 3. it's thread safe
\*/
private final SseBroadcaster broadcaster = new SseBroadcaster();
private static final EventCoordinator INSTANCE = new EventCoordinator();
public static EventCoordinator getInstance() {
return INSTANCE;
}
/\*\*
\* add to SSE broadcaster list of clients/subscribers
\* [@return](https://forums.oracle.com/ords/apexds/user/return) EventOutput which will keep the connection open.
\*
\* Note: broadcaster.add(output) is a slow operation
\* Please see ([https://jersey.java.net/apidocs/2.23.2/jersey/org/glassfish/jersey/server/Broadcaster.html#add(org.glassfish.jersey.server.BroadcasterListener](https://jersey.java.net/apidocs/2.23.2/jersey/org/glassfish/jersey/server/Broadcaster.html#add(org.glassfish.jersey.server.BroadcasterListener)))
\*/
public EventOutput subscribe() {
final EventOutput eOutput = new EventOutput();
broadcaster.add(eOutput);
LOGGER.log(Level.INFO, "Client Subscribed successfully {0}", eOutput.toString());
return eOutput;
}
/\*\*
\* broadcast record details to all connected clients
\* [@param](https://forums.oracle.com/ords/apexds/user/param) record kafka record obtained from broker
\*/
public void broadcast(ConsumerRecord\<String, String> record) {
OutboundEvent.Builder eventBuilder = new OutboundEvent.Builder();
OutboundEvent event = eventBuilder.name(record.key())
.id(String.valueOf(record.offset()))
.data(String.class, record.value()+"%")
.comment("Partition "+Integer.toString(record.partition()))
.mediaType(MediaType.TEXT\_PLAIN\_TYPE)
.build();
broadcaster.broadcast(event);
LOGGER.log(Level.INFO, "Broadcasted record {0}", record);
}
}
The Jersey SSE Broadcaster is used because of its following characteristics
- it tracks client statistics
- automatically disposes server resources if clients disconnect
- it's thread safe
Deploy to Oracle Application Container Cloud
Now that you have a fair idea of the application, it’s time to look at the build, packaging & deployment
Metadata files
manifest.json: You can use this file in its original state (for both producer and consumer microservices)
{
"runtime": {
"majorVersion": "8"
},
"command": "java -jar accs-kafka-producer.jar",
"release": {
"build": "12042016.1400",
"commit": "007",
"version": "0.0.1"
},
"notes": "Kafka Producer powered by Oracle Application Container Cloud"
}
{
"runtime": {
"majorVersion": "8"
},
"command": "java -jar accs-kafka-consumer.jar",
"release": {
"build": "12042016.1400",
"commit": "007",
"version": "0.0.1"
},
"notes": "Kafka consumer powered by Oracle Application Container Cloud"
}
deployment.json
It contains environment variable corresponding to your Kafka broker. The value is left as a placeholder for the user to fill prior to deployment.
{
"environment": {
"KAFKA\_CLUSTER":"\<as-configured-in-kafka-server-properties>"
}
}
This value (Oracle Compute Cloud instance public DNS) should be the same as the one you configured in the advertised.listeners attribute of the Kafka server.properties file
Please refer to the following documentation for more details on metadata files
Build & zip
Build JAR and zip it with (only) the manifest.json file to create a cloud-ready artifact
Producer application
cd <code_dir>/producer //maven project directory
mvn clean install
zip accs-kafka-producer.zip manifest.json target/accs-kafka-producer.jar //you can also use tar to create a tgz file
Consumer application
cd <code_dir> //maven project directory
mvn clean install
zip accs-kafka-consumer.zip manifest.json target/accs-kafka-consumer.jar
Upload application zip to Oracle Storage cloud
You would first need to upload your application ZIP file to Oracle Storage Cloud and then reference it in the subsequent steps. Here are the required the cURL commands
Create a container in Oracle Storage cloud (if it doesn't already exist)
curl -i -X PUT -u <USER_ID>:<USER_PASSWORD> <STORAGE_CLOUD_CONTAINER_URL>
e.g. curl -X PUT –u jdoe:foobar "https://domain007.storage.oraclecloud.com/v1/Storage-domain007/accs-kafka-consumer/"
Upload your zip file into the container (zip file is nothing but a Storage Cloud object)
curl -X PUT -u <USER_ID>:<USER_PASSWORD> <STORAGE_CLOUD_CONTAINER_URL> -T <zip_file> "<storage_cloud_object_URL>" //template
e.g. curl -X PUT –u jdoe:foobar -T accs-kafka-consumer.zip "https://domain007.storage.oraclecloud.com/v1/Storage-domain007/accs-kafka-consumer/accs-kafka-consumer.zip"
Repeat the same for the producer microservice
Deploy to Application Container Cloud
Once you have finished uploading the ZIP, you can now reference its (Oracle Storage cloud) path while using the Application Container Cloud REST API which you would use in order to deploy the application. Here is a sample cURL command which makes use of the REST API
curl -X POST -u joe@example.com:password \
-H "X-ID-TENANT-NAME:domain007" \
-H "Content-Type: multipart/form-data" -F "name=accs-kafka-consumer" \
-F "runtime=java" -F "subscription=Monthly" \
-F "deployment=@deployment.json" \
-F "archiveURL=accs-kafka-consumer/accs-kafka-consumer.zip" \
-F "notes=notes for deployment" \