Hello everyone,
I have been facing a bug of Oracle JDBC Driver while migrating data from Oracle to MariaDB.
My Oracle database uses WE8ISO8859P15 and the description from oracle documentation says;
If the database character set is US7ASCII or WE8ISO8859P1__, then the data is transferred to the client without any conversion. The driver then converts the character set to UCS-2 in Java.
If the database character set is something other than US7ASCII or WE8ISO8859P1__, then the server first translates the data to UTF-8 before transferring it to the client. On the client, the JDBC Thin driver converts the data to UCS-2 in Java.
Advanced Topics (0 Bytes)So according to this documentation, my CP1252 characters will be converted to UCS-2 (UTF-16) in the driver at the and.
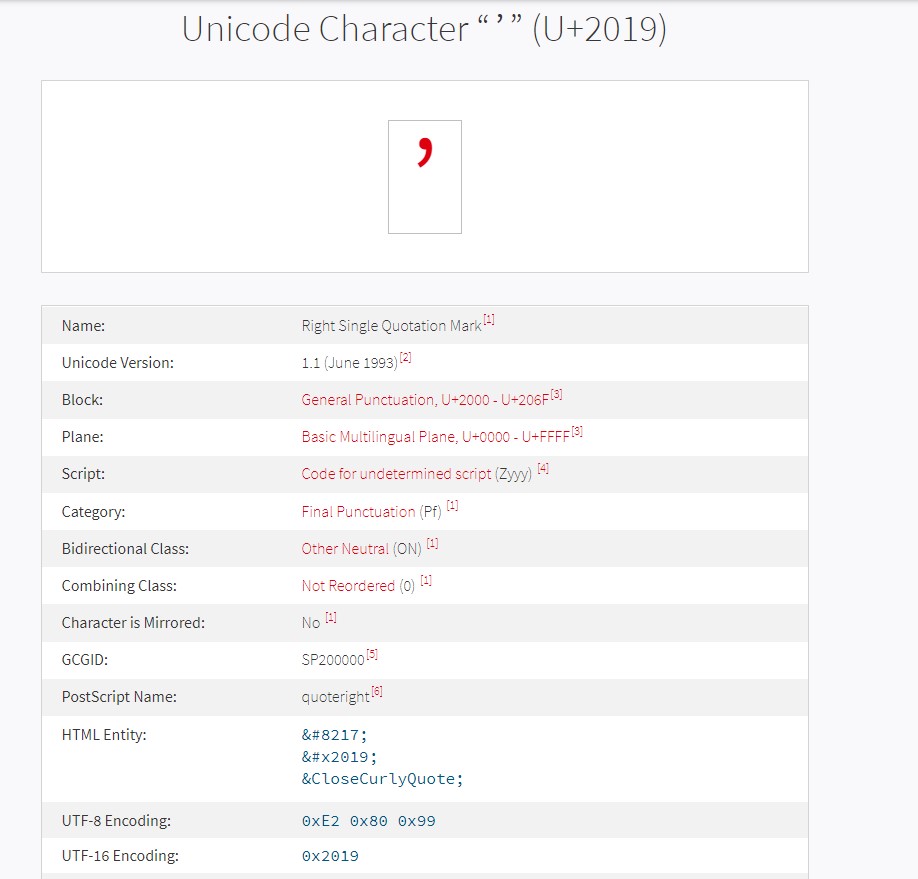
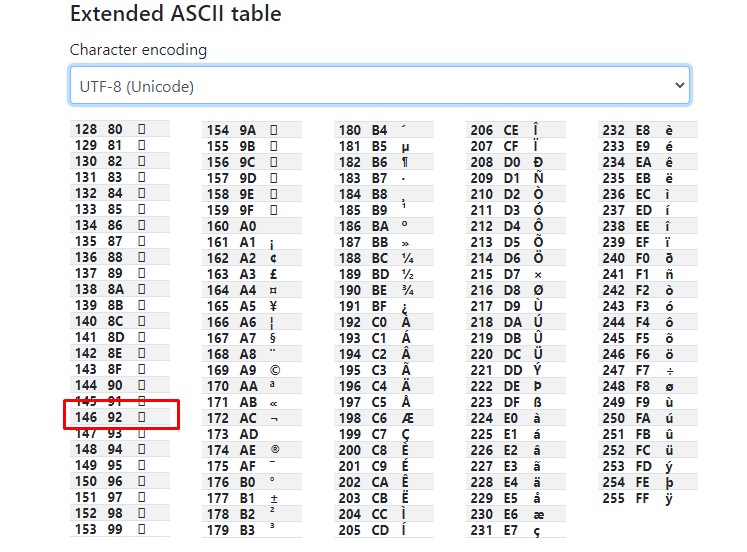
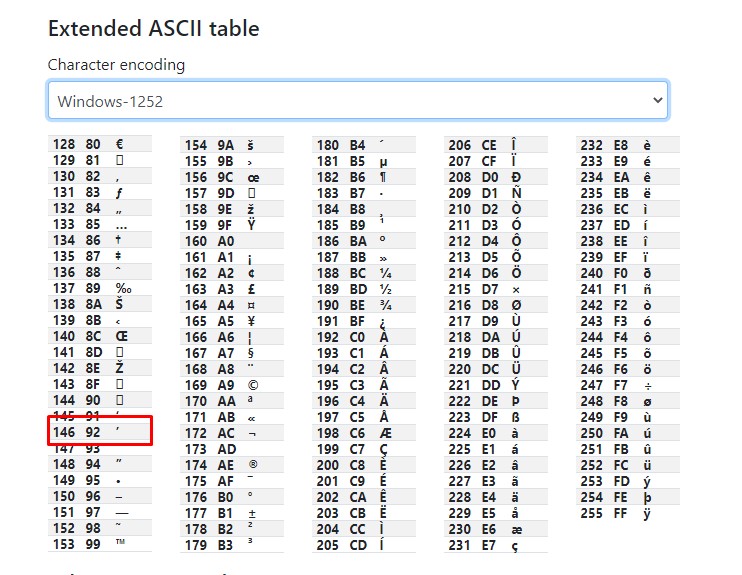
I have CHR(146) character which is an apostrophe character in the Oracle database and when I use the JDBC driver to get it by using the following code it converts my CHR(146) apostrophe character to Unicode CHR(146) square instead of converting Unicode apostrophe character and this causes character loss
textRead = rs.getString("TEXT");
If I get raw bytes first and make the conversion myself by using the following lines it works as expected.
byte[] rawbytes = rs.getBytes("TEXT");
textRead = new String(rawbytes, "Cp1252");
But this conversion should have been done by the Oracle JDBC Driver automatically according to the documentation without any additional conversion.
Since I have the latin1 MariaDB database on the target and the latin1 character set does not contain Unicode CHR(146) characters I am getting the following error.
java.sql.SQLException: Incorrect string value: '\xC2\x92' for column 'text' at row 1
Can you please have a look at this and verify if it is a bug or I am missing a driver setting?