Tectonic shifts in the technology space usually precipitate out of a necessity or a desire to change the status quo. Big data, as we know it today is one
such tectonic shift that was a result of the necessity to keep up with the deluge of data - a result of automation of pretty much everything that touches our life today.
Big data encompasses data sets that are large and complex such that traditional data processing cannot keep up (think petabytes and exabytes of data). It
matters in the Oracle Bare Metal Cloud Service context because cloud has been the accelerator for big data adoption and making it accessible to all. Big data
belongs in the cloud. The elasticity of the cloud makes the use of big data analysis practical and the scalability, durability and cost effectiveness of object storage
makes it possible to store data at the ‘big data’ scale.
The performance characteristics, cost effectiveness, and processing prowess of the Bare Metal Cloud make it the platform of choice to run all your big data workloads.
The Mapreduce reference architecture was the harbinger of all things big data. It was the first step to re-imagining how data should be analyzed at cloud scale. Apache
Hadoop brought this dynamic, distributed, and highly scalable framework to open source. With built-in fault tolerance and high scalability, this framework became the cornerstone
of big data infrastructure and over a period of time it has spawned development of different interfaces such as Hive, Spark, Presto, and others in the community. Engineers at
Facebook first democratized this framework with Hive and made big data available and accessible to data users beyond developers. Since then engines such as Spark have
emerged to fill the needs of data scientists while solutions like Presto and Impala have become popular solutions for Analysts.
Today, I am very excited to let you know that in addition to supporting DIY big data workloads, Bare Metal Cloud Service now also supports a turnkey, cloud scale big data-as-a-Service
solution. We have accomplished this by integrating with Qubole’s big data-as-a-service platform ‘Qubole Data Service’ (QDS). Qubole knows a thing or two about big data processing at
scale. It was founded by the same engineers who introduced Hive to Facebook and the Hadoop ecosystem. They were the architects of the Facebook data infrastructure, which today
supports 1.85 billion users. In its five years of existence, QDS has scaled to process almost 500 petabytes of data each month.
Oracle Bare Metal Cloud Services and Qubole together, offer a compelling big data solution for enterprises that wish to gain a competitive edge by
generating business insights and making their data work for them.
DIY big data or a turnkey solution – your choice
We like to give our customers choice. You can take two routes to standing up your big data infrastructure on Oracle Bare Metal Cloud Services:
-
DIY big data: You can select the Hadoop distribution of your choice, run it on Bate Metal Cloud compute service and stitch together the solution using multiple off-the-shelf products
and tools. We’ll describe this in detail in later posts.
-
Oracle IaaS big data solution with Qubole: This solution offers you a turnkey, fully managed, self-service big data solution on Bare Metal Cloud. If you choose Qubole,
you will be able to delegate all the groundwork associated with standing up big data infrastructure in the cloud to the Bare Metal Cloud team. Qubole Data Service
will enable you to go from 0 to query in 5 short steps.
Seven great things about the Oracle and Qubole big data solution
-
A fully turnkey Solution: Qubole on Bare Metal Cloud Services (BMCS) is a fully managed, turnkey, big data solution. You don’t need to install, configure, or deploy a big data
infrastructure to get results out of your data. Just sign up for BMCS and Qubole, define the clusters’ characteristics, and start submitting queries. Qubole manages the rest for you.
-
Separation of compute and storage: Qubole uses data stored in the Object Storage. Data processing is not tied to where the data resides. This separation allows Qubole to
scale compute independent of storage and vice versa. This provides the elasticity and agility needed for big data processing.
-
Auto-scaling: Qubole scales resources up and down, based on customer defined policies, adapting the cluster size to the workload. This saves costs, reduces complexity and
increases agility.
-
Automatic cluster management: When a new workload starts, Qubole determines if a new cluster is required and automatically starts it. It monitors when the cluster nodes need
to scale up, and uses an auto-scaling algorithm to adapt the cluster’s size to the workload needs. Finally, when the job is done, Qubole auto terminates cluster, without user intervention
-
Multi-engine support: Qubole support multiple big data processing engines. At GA, we offer support for Hadoop, Hive, and Spark. Support for Presto is coming soon.
-
Management interfaces: Manage big data infrastructure using UI, REST APIs and Python SDK
-
And did I mention scale : Qubole can easily scale to run thousands of big data nodes on BMCS. It operates at cloud scale.
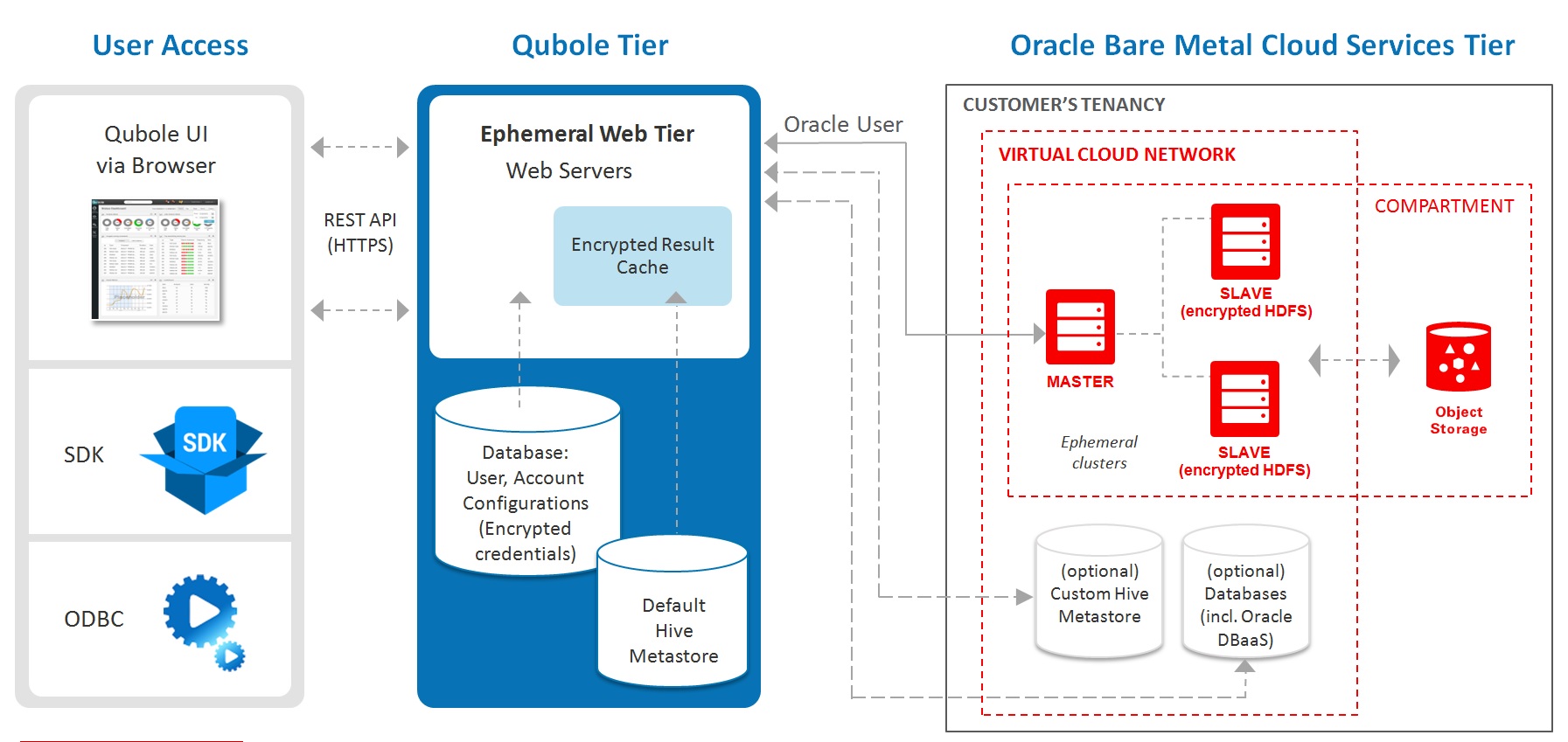
Oracle and Qubole high level architecture
Qubole offers native integration with the Oracle IaaS platform. The solution consists of three components
**- Bare Metal Cloud Services infrastructure**: This is basic compute, storage, networking infrastructure layer, where your data will be hosted
and where the Hadoop clusters will run. You own the resources in your BMCS tenancy, at all times but Qubole manages it on your behalf using
an IAM user that you create, specifically for this purpose.
- Qubole Tier: This is where the QDS engine is hosted. It drives activities like provisioning, orchestration, management, auto scaling, data visualization etc
- User Access tier: The customer manages their big data infrastructure via the user access layer. Users have a choice to manage their big data
infrastructure via the UI (using a browser based interface) or an SDK. ODBC drivers are supported as well.
Four steps to starting your Oracle IaaS big data solution with Qubole
Getting started is a quick and easy. You can have you big data infrastructure up and running in a matter of hours.
Step #1: Create a BMCS account here and setup your tenancy to host Qubole big data clusters
Once you establish access to your Bare Metal Cloud Services account, log into the service console and set up your tenancy for Qubole to initialize your big
data infrastructure. You’ll need to do the following
- Create compartments where your big data clusters will be hosted
- Create a new BMCS user
- Create a new user group and assign the newly create BMCS user to the group
- Create a public/private key pair and upload the public key to BMCS
- Configure the Virtual Cloud Network
- Set access policies on the compartment
Be sure that you are closely following the instructions posted in the Qubole ‘quick start guide’ for smooth sailing.
Once the setup is done, identify the bucket in the Bare Metal Cloud object storage that hosts your data, or create a bucket in the Bare Metal Cloud Service console and import your data into the bucket.
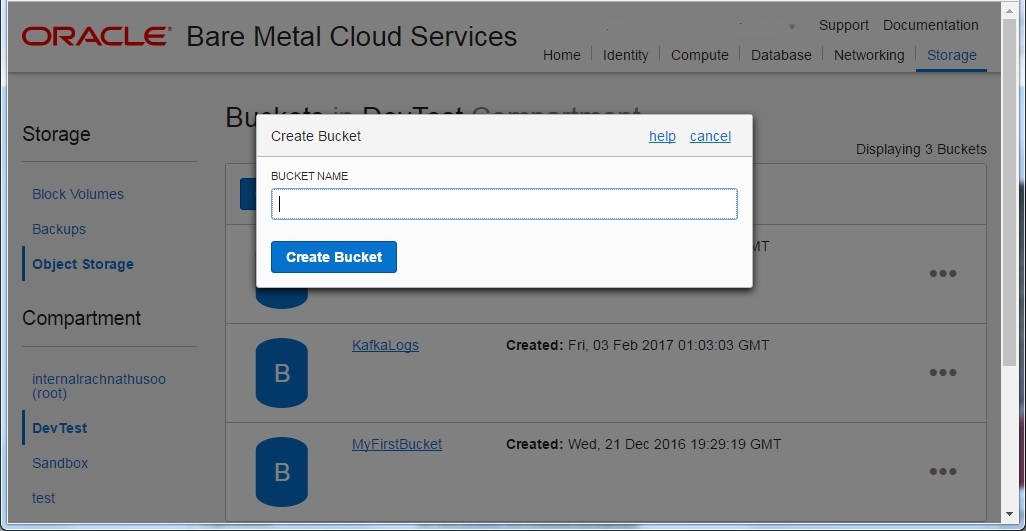
Step # 2: Create a Qubole - Oracle account
Click here to establish your Qubole-Oracle account. You will receive a confirmation email from Qubole that will provide the log in details as well as
the link to the Qubole on BMCS service console.

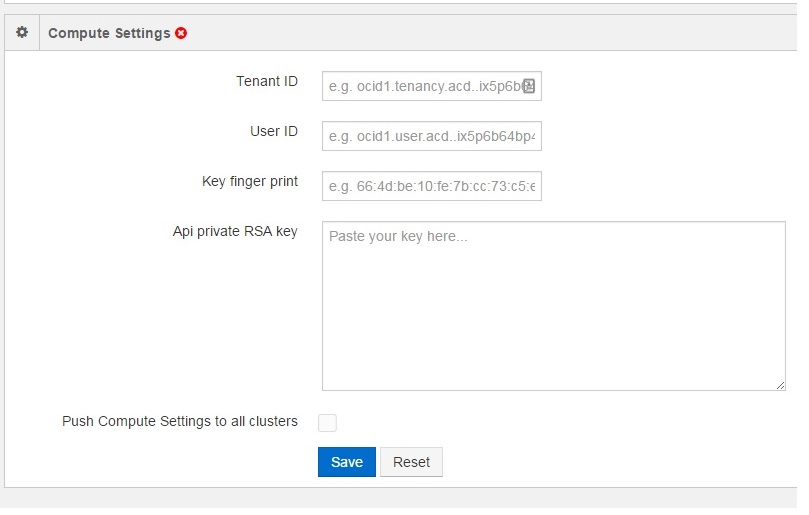
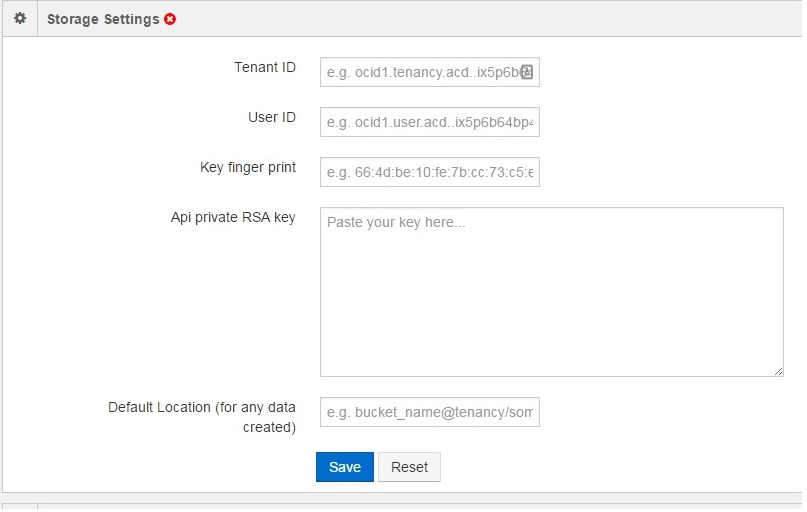
Step # 3: Input your Bare Metal Cloud Tenancy details into the Qubole service console
The compute and storage settings can be same of different, depending on whether a single or multiple users control access to the storage and compute resources.
Step # 4: Start analyzing your data
You are all set, you can now start running queries to analyze your data, schedule jobs and visualize data to detect patterns.
- Create a cluster configuration
\- Create the Hive metastore and submit queries, via the ‘QDS Analyze’. You can also choose to recurring jobs via the ‘QDS Scheduler’
- Monitor your jobs
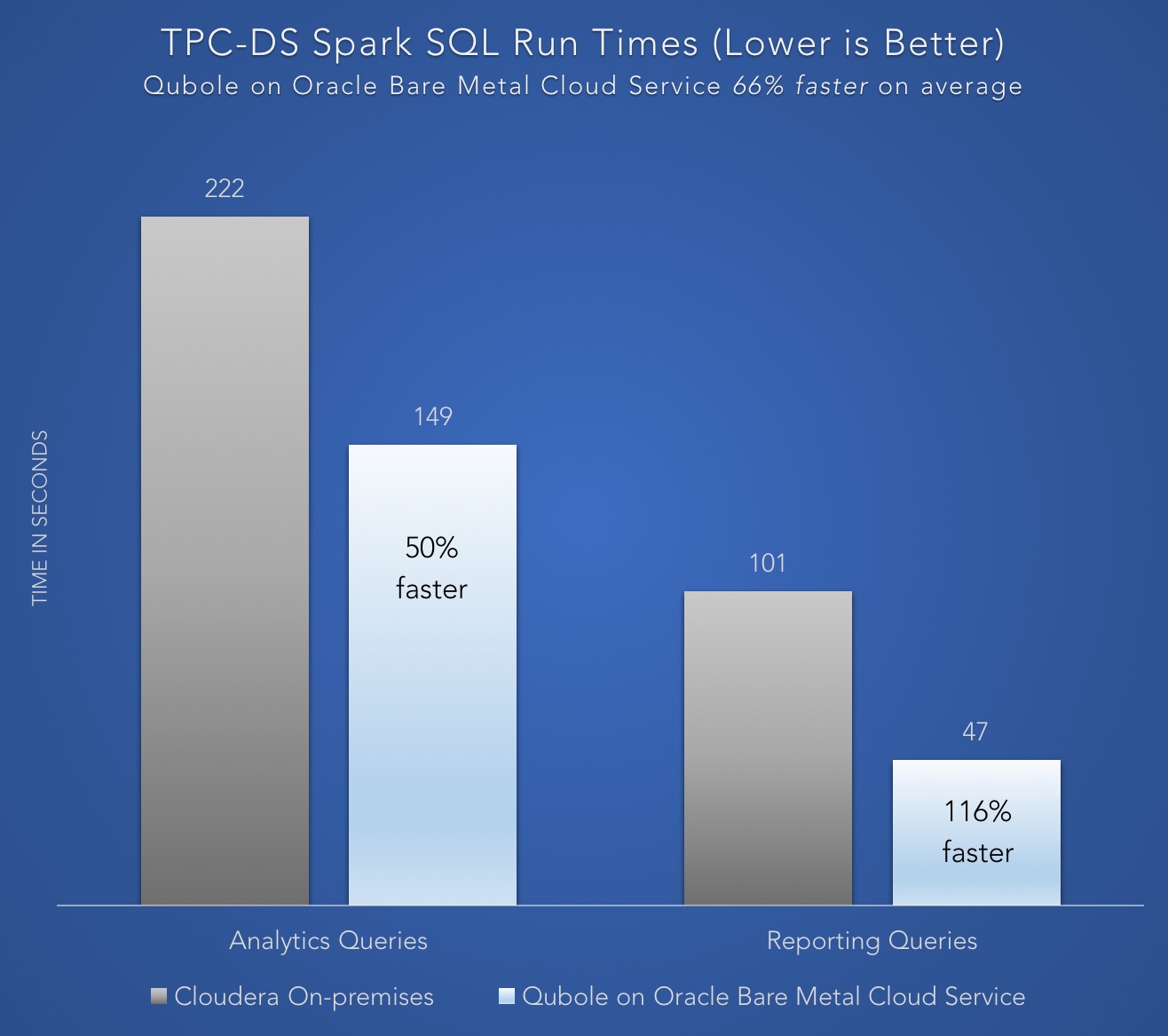
Blazing fast Spark performance
Workloads just run better on Oracle Bare Metal Cloud Services and we have a benchmark to prove it. Qubole on BMCS runs Spark SQL 116% faster than
comparable solution on-premises.
Sample Data sets
Just in case you want to give our big data solution a test run and are looking for some sample data, here are some of the public data sets that you can download
Give it a try!
In summary, the Bare Metal Cloud Services team is invested in offering customers choice. We built our infrastructure to handle the most demanding workloads. Infrastructure
as Service primitives like compute (with blazing fast NVMe storage), block storage, object storage and networking were purposely architected to efficiently host big data workloads.
So whether you are gravitating towards standing up your own big data cluster on BMCS or leveraging Qubole as your turnkey big data solution of choice, we have you covered.
Go ahead, I encourage you to take big data out for a spin and see how it works for you. If you need help, feel free to reach out to us either by commenting below, on stack overflow,
or reach out to your Oracle account manager so that they can get you in direct contact with us.
Rachna Thusoo
Director, Product Management
Oracle Bare Metal Cloud Team