Hi I have a table with keys and corresponding values but if a key with one values also appears with another (related but different) value I want to delete the later row
Table:
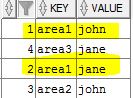
related values table

I wrote a PL/SQL function to do this
declare
v_count number;
v_duplicate_value RELATED_VALUES.VALUE2%type;
BEGIN
SELECT count(*) INTO v_count from one where value = 'john' and key = 'area1';
if v_count > 0 then
select value2 into v\_duplicate\_value from related\_values where value1 = 'john';
delete from one where value = v\_duplicate\_value and key = 'area1';
end if;
end;
after the procedure

I want to know if I can do this with SQL.
I will greatly appreciate any help. Thanks in advance.
CREATE TABLE "ONE"
( "ID" NUMBER,
"KEY" VARCHAR2(200 BYTE),
"VALUE" VARCHAR2(200 BYTE)
) ;
CREATE TABLE "RELATED_VALUES"
( "ID" NUMBER,
"VALUE1" VARCHAR2(200 BYTE),
"VALUE2" VARCHAR2(200 BYTE)
) ;
Insert into ONE (ID,KEY,VALUE) values (1,'area1','john');
Insert into ONE (ID,KEY,VALUE) values (2,'area1','jane');
Insert into ONE (ID,KEY,VALUE) values (4,'area3','jane');
Insert into ONE (ID,KEY,VALUE) values (3,'area2','john');
Insert into RELATED_VALUES (ID,VALUE1,VALUE2) values (11,'john','jane');
Message was edited by: Anuswadh - removed the schema name from create and insert statements