This is more of a discussion with about 2 relative questions than something absolute - feel free to skip by it as i'm asking to better my own understanding... it may require a bit of reading. Okay then:Does sorting add considerable overhead, in and of itself?
I'm talking about mid sized to large tables. Let's go under the assumption of non indexed column. Now from the article
I'm reading I will post 2 parts. First what I am interested in and than an excerpt for the full context if you need to read that.
Next, let's look at what Oracle Database can do conceptually with a top- N query:
select * from (select * from t
order by unindexed_column)
where ROWNUM < :N;
In this case, Oracle Database will take these steps:
1. Run a full-table scan on T, as before (you cannot avoid this step).
2. In an array of : N elements, sort only : N rows.
The first N rows will populate this array of rows in sorted order. When the N +1 row is fetched, it will be compared to the last row in the array. If it would go into slot N +1 in the array, it gets thrown out. Otherwise, it is added to this array and sorted and one of the existing rows is discarded. Your sort area holds N rows maximum, so instead of sorting one million rows, you sort N rows.
This seemingly small detail of using an array concept and sorting just N rows can lead to huge gains in performance and resource usage. It takes a lot less RAM to sort 10 rows than it does to sort one million rows (not to mention TEMP space usage).
Now that bolded part is telling me that it is comparing N+1 th element to a previous set of N elements. I'm assuming this would do it for each row then, whereas each row is N+1.
Now here's the full context or you can skip to my question in the end.
Using the top- N query means that you have given the database extra information. You have told it, "I'm interested only in getting N rows; I'll never consider the rest." Now, that doesn't sound too earth-shattering until you think about sorting—how sorts work and what the server would need to do. Let's walk through the two approaches with a sample query:
select * from t
order by unindexed_column;
Now, assume that T is a big table, with more than one million records, and each record is "fat"—say, 100 or more bytes. Also assume that UNINDEXED_COLUMN is, as its name implies, a column that is not indexed. And assume that you are interested in getting just the first 10 rows. Oracle Database would do the following:
1. Run a full-table scan on T.
2. Sort T by UNINDEXED_COLUMN. This is a full sort.
3. Presumably run out of sort area memory and need to swap temporary extents to disk.
4. Merge the temporary extents back to get the first 10 records when they are requested.
5. Clean up (release) the temporary extents as you are finished with them.
Now, that is a lot of I/O. Oracle Database has most likely copied the entire table into TEMP and written it out, just to get the first 10 rows.
Next, let's look at what Oracle Database can do conceptually with a top- N query:
select * from
(select * from t order by unindexed_column)
where ROWNUM < :N;
In this case, Oracle Database will take these steps:
1. Run a full-table scan on T, as before (you cannot avoid this step).
2. In an array of : N elements (presumably in memory this time), sort only : N rows.
The first N rows will populate this array of rows in sorted order. When the N +1 row is fetched, it will be compared to the last row in the array. If it would go into slot N +1 in the array, it gets thrown out. Otherwise, it is added to this array and sorted and one of the existing rows is discarded. Your sort area holds N rows maximum, so instead of sorting one million rows, you sortN rows.
This seemingly small detail of using an array concept and sorting just N rows can lead to huge gains in performance and resource usage. It takes a lot less RAM to sort 10 rows than it does to sort one million rows (not to mention TEMP space usage).
Using the following table T, you can see that although both approaches get the same results, they use radically different amounts of resources:
create table t as select dbms_random.value(1,1000000) id, rpad('*',40,'*' ) data from dual connect by level <= 100000; begin dbms_stats.gather_table_stats ( user, 'T'); end; / Now enable tracing, via exec dbms_monitor.session_trace_enable (waits=>true);
And then run your top- N query with ROWNUM:
select * from
(select * from t order by id)
where rownum <= 10;
And finally run a "do-it-yourself" query that fetches just the first 10 records:
declare cursor c is select * from t order by id; l_rec c%rowtype; begin open c; for i in 1 .. 10 loop fetch c into l_rec; exit when c%notfound; end loop; close c; end; /
After executing this query, you can use TKPROF to format the resulting trace file and review what happened. First examine the top- N query, as shown in Listing 1.
Code Listing 1: Top- N query using ROWNUM
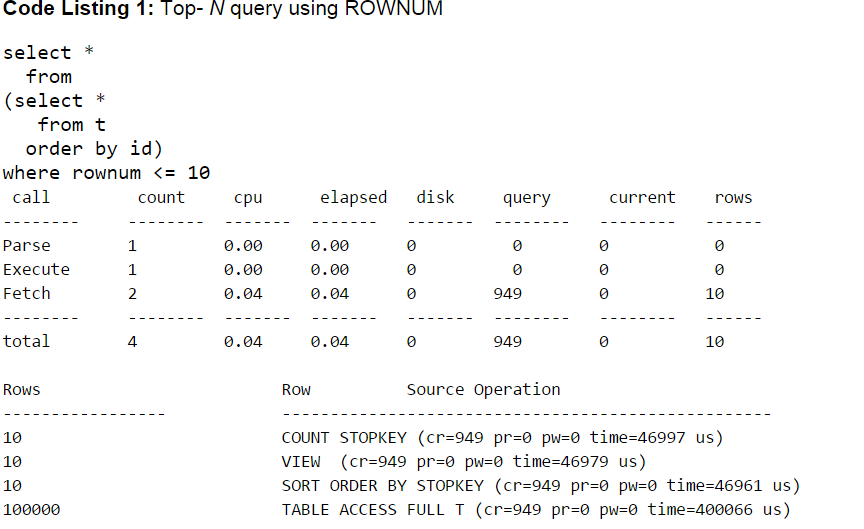
The query read the entire table (because it had to), but by using the SORT ORDER BY STOPKEY step, it was able to limit its use of temporary space to just 10 rows. Note the final Row Source Operation line—it shows that the query did 949 logical I/Os in total (cr=949), performed no physical reads or writes (pr=0 and pw=0), and took 400066 millionths of a second (0.04 seconds). Compare that with the do-it-yourself approach shown in Listing 2.
Code Listing 2: Do-it-yourself query without ROWNUM

As you can see, this result is very different. Notably, the elapsed/CPU times are significantly higher, and the final Row Source Operation lines provide insight into why this is.
MY QUESTION:
Form the explain plan outputs you can tell there is a significant difference in top-n sorts and non-top-N sorts on this table.
To me it seems like there would be some considerable overhead in comparing N+1 row to a set of N rows to see if the N+1 row should be part of the set. Note this probably changes the last value in the set of N rows quite often which takes even more overhead. After seeing the outputs it seems like a lot of overhead is devoted to sorting. To me this seemed a bit odd at first. I haven't seen much on sort overhead in the literature (outside of complex query or DML performance). Maybe because uninteresting topic to some or maybe because indexes are more than likely for scenarios like this.
Can sorting really be that much of a problem for database overhead? Lets throw out the idea of bitmap indexes, indexes in general... Sorting the full set of rows in this case seemed to generate so much more overhead than the top-N method even though the top-N method added the step of comparing nth row to a set of N rows to see it the nth row belonged in there. This seemed odd to me.
Oh forgot this part. here is the article: Ask Tom: On ROWNUM and Limiting Results