Hi, I'm new to analytic functions, and there's something I don't understand about their performance compared to aggregation functions.
I have a LINEITEM table with 1,800,093 rows, and I am trying to find any row whose l_extendedprice is within the range of min(l_extendedprice) and max(l_extendedprice).
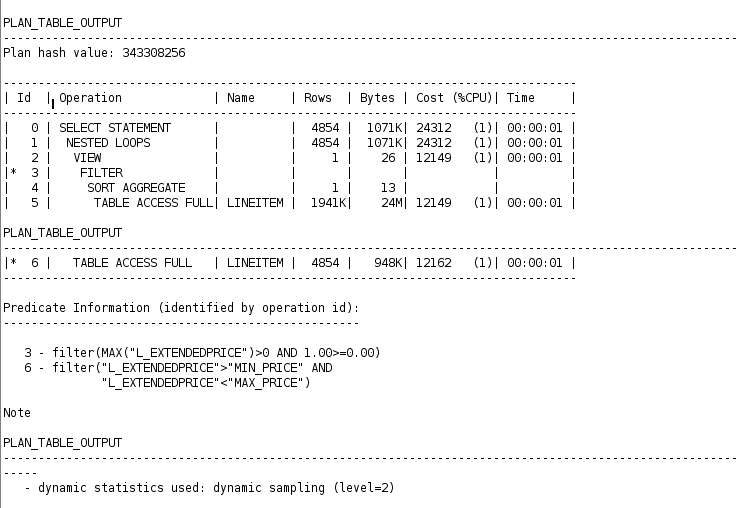
I have tried two queries, one with an aggregation function and one with an analytic function, and there's a significant difference in terms of the CPU costs when I list the query processing plans.
The query that uses the aggregation function is as follows:

 The query that uses analytic functions is as follows:
The query that uses analytic functions is as follows:

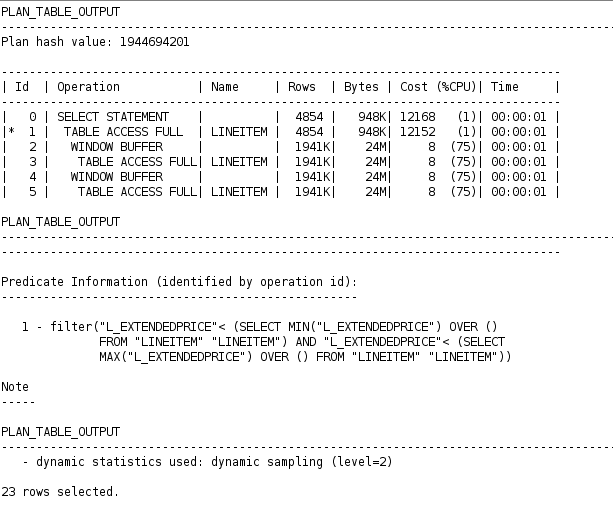 Can anyone please help me explain the difference in terms of CPU costs? Why does the second query cost less even though it is trying to access the table three times, while the first query only accesses the table twice?
Can anyone please help me explain the difference in terms of CPU costs? Why does the second query cost less even though it is trying to access the table three times, while the first query only accesses the table twice?
My best guess is that the second query reads the data into the buffer, sorts the data for the first time to find the min_price, then uses the previously sorted data which is still in the buffer to find the max_price. It might explain why the first table access full for the second query is expensive but the subsequence operations are not. But I am not sure if that's the case, and I couldn't find any source that would support my guess.
Can anyone please help me explain it? I would deeply appreciate it.